back to index
Andrey Karpathy. Neural Networks: Zero to Hero
Episode 4. Building makemore Part 3: Activations & Gradients, BatchNorm
link |
Today we are continuing our implementation of Make More.
link |
Now in the last lecture,
link |
we implemented the multilayer perceptron
link |
along the lines of Benjou et al. 2003
link |
for character level language modeling.
link |
So we followed this paper,
link |
took in a few characters in the past,
link |
and used an MLP to predict the next character in a sequence.
link |
So what we'd like to do now
link |
is we'd like to move on to more complex
link |
and larger neural networks, like recurrent neural networks
link |
and their variations like the GRU, LSTM, and so on.
link |
Now, before we do that though,
link |
we have to stick around the level of multilayer perceptron
link |
And I'd like to do this
link |
because I would like us to have
link |
a very good intuitive understanding
link |
of the activations in the neural net during training,
link |
and especially the gradients that are flowing backwards
link |
and how they behave and what they look like.
link |
This is going to be very important
link |
to understand the history of the development
link |
of these architectures,
link |
because we'll see that recurrent neural networks,
link |
while they are very expressive
link |
in that they are a universal approximator
link |
and can in principle implement all the algorithms,
link |
we'll see that they are not very easily optimizable
link |
with the first-order gradient-based techniques
link |
that we have available to us and that we use all the time.
link |
And the key to understanding
link |
why they are not optimizable easily
link |
is to understand the activations and the gradients
link |
and how they behave during training.
link |
And we'll see that a lot of the variants
link |
since recurrent neural networks
link |
have tried to improve that situation.
link |
And so that's the path that we have to take,
link |
and let's get started.
link |
So the starting code for this lecture
link |
is largely the code from before,
link |
but I've cleaned it up a little bit.
link |
So you'll see that we are importing
link |
all the torch and matplotlib utilities.
link |
We're reading in the words just like before.
link |
These are eight example words.
link |
There's a total of 32,000 of them.
link |
Here's a vocabulary of all the lowercase letters
link |
and the special dot token.
link |
Here we are reading the dataset and processing it
link |
and creating three splits,
link |
the train dev and the test split.
link |
Now in the MLP, this is the identical same MLP,
link |
except you see that I removed
link |
a bunch of magic numbers that we had here.
link |
And instead we have the dimensionality
link |
of the embedding space of the characters
link |
and the number of hidden units in the hidden layer.
link |
And so I've pulled them outside here
link |
so that we don't have to go and change
link |
all these magic numbers all the time.
link |
With the same neural net with 11,000 parameters
link |
that we optimize now over 200,000 steps
link |
with a batch size of 32.
link |
And you'll see that I refactored the code here a little bit,
link |
but there are no functional changes.
link |
I just created a few extra variables, a few more comments,
link |
and I removed all the magic numbers.
link |
And otherwise it's the exact same thing.
link |
Then when we optimize,
link |
we saw that our loss looked something like this.
link |
We saw that the train and val loss were about 2.16 and so on.
link |
Here I refactored the code a little bit
link |
for the evaluation of arbitrary splits.
link |
So you pass in a string of which split
link |
you'd like to evaluate.
link |
And then here, depending on train, val, or test,
link |
I index in and I get the correct split.
link |
And then this is the forward pass of the network
link |
and evaluation of the loss and printing it.
link |
So just making it nicer.
link |
One thing that you'll notice here is
link |
I'm using a decorator torch.nograd,
link |
which you can also look up and read documentation of.
link |
Basically what this decorator does on top of a function
link |
is that whatever happens in this function
link |
is assumed by a torch to never require any gradients.
link |
So it will not do any of the bookkeeping
link |
that it does to keep track of all the gradients
link |
in anticipation of an eventual backward pass.
link |
It's almost as if all the tensors that get created here
link |
have a requires grad of false.
link |
And so it just makes everything much more efficient
link |
because you're telling torch that I will not call
link |
dot backward on any of this computation,
link |
and you don't need to maintain the graph under the hood.
link |
So that's what this does.
link |
And you can also use a context manager with torch.nograd,
link |
and you can look those up.
link |
Then here we have the sampling from a model,
link |
just as before, just a forward pass of a neural net,
link |
getting the distribution, sampling from it,
link |
adjusting the context window,
link |
and repeating until we get the special end token.
link |
And we see that we are starting to get
link |
much nicer looking words sampled from the model.
link |
It's still not amazing,
link |
and they're still not fully name-like,
link |
but it's much better than what we had
link |
to do with the bigram model.
link |
So that's our starting point.
link |
Now, the first thing I would like to scrutinize
link |
is the initialization.
link |
I can tell that our network
link |
is very improperly configured at initialization,
link |
and there's multiple things wrong with it,
link |
but let's just start with the first one.
link |
Look here on the zeroth iteration,
link |
the very first iteration,
link |
we are recording a loss of 27,
link |
and this rapidly comes down to roughly one or two or so.
link |
So I can tell that the initialization is all messed up
link |
because this is way too high.
link |
In training of neural nets,
link |
it is almost always the case
link |
that you will have a rough idea
link |
for what loss to expect at initialization,
link |
and that just depends on the loss function
link |
and the problem setup.
link |
In this case, I do not expect 27.
link |
I expect a much lower number,
link |
and we can calculate it together.
link |
Basically, at initialization,
link |
what we'd like is that there's 27 characters
link |
that could come next for any one training example.
link |
At initialization, we have no reason to believe
link |
any characters to be much more likely than others,
link |
and so we'd expect that the probability distribution
link |
that comes out initially is a uniform distribution
link |
assigning about equal probability to all the 27 characters.
link |
So basically what we'd like is the probability
link |
for any character would be roughly one over 27.
link |
That is the probability we should record,
link |
and then the loss is the negative log probability.
link |
So let's wrap this in a tensor,
link |
and then then we can take the log of it,
link |
and then the negative log probability
link |
is the loss we would expect,
link |
which is 3.29, much, much lower than 27.
link |
And so what's happening right now
link |
is that at initialization,
link |
the neural net is creating probability distributions
link |
that are all messed up.
link |
Some characters are very confident,
link |
and some characters are very not confident.
link |
And then basically what's happening
link |
is that the network is very confidently wrong,
link |
and that's what makes it record very high loss.
link |
So here's a smaller four-dimensional example of the issue.
link |
Let's say we only have four characters,
link |
and then we have logics that come out of the neural net,
link |
and they are very, very close to zero.
link |
Then when we take the softmax of all zeros,
link |
we get probabilities that are a diffused distribution.
link |
So sums to one and is exactly uniform.
link |
And then in this case, if the label is say two,
link |
it doesn't actually matter if the label is two,
link |
or three, or one, or zero,
link |
because it's a uniform distribution.
link |
We're recording the exact same loss, in this case, 1.38.
link |
So this is the loss we would expect
link |
for a four-dimensional example.
link |
And I can see, of course,
link |
that as we start to manipulate these logics,
link |
we're going to be changing the loss here.
link |
So it could be that we lock out,
link |
and by chance, this could be a very high number,
link |
like five or something like that.
link |
Then in that case, we'll record a very low loss
link |
because we're assigning the correct probability
link |
at initialization by chance to the correct label.
link |
Much more likely it is that some other dimension
link |
will have a high logit.
link |
And then what will happen
link |
is we start to record much higher loss.
link |
And what can happen is basically the logits come out
link |
like something like this,
link |
and they take on extreme values,
link |
and we record really high loss.
link |
For example, if we have tors.random of four,
link |
so these are normally distributed numbers, four of them.
link |
Then here, we can also print the logits,
link |
probabilities that come out of it, and the loss.
link |
And so because these logits are near zero,
link |
for the most part, the loss that comes out is okay.
link |
But suppose this is like times 10 now.
link |
You see how, because these are more extreme values,
link |
it's very unlikely that you're going to be guessing
link |
the correct bucket, and then you're confidently wrong
link |
and recording very high loss.
link |
If your logits are coming up even more extreme,
link |
you might get extremely insane losses,
link |
like infinity even at initialization.
link |
So basically, this is not good,
link |
and we want the logits to be roughly zero
link |
when the network is initialized.
link |
In fact, the logits don't have to be just zero,
link |
they just have to be equal.
link |
So for example, if all the logits are one,
link |
then because of the normalization inside the softmax,
link |
this will actually come out okay.
link |
But by symmetry, we don't want it to be
link |
any arbitrary positive or negative number,
link |
we just want it to be all zeros
link |
and record the loss that we expect at initialization.
link |
So let's now concretely see
link |
where things go wrong in our example.
link |
Here we have the initialization.
link |
Let me reinitialize the neural net, and here, let me break
link |
after the very first iteration,
link |
so we only see the initial loss, which is 27.
link |
So that's way too high, and intuitively,
link |
now we can expect the variables involved,
link |
and we see that the logits here,
link |
if we just print some of these,
link |
if we just print the first row,
link |
we see that the logits take on quite extreme values,
link |
and that's what's creating the fake confidence
link |
in incorrect answers and making it hard for us
link |
to get the correct answer, and that makes the loss
link |
get very, very high.
link |
So these logits should be much, much closer to zero.
link |
So now let's think through how we can achieve logits
link |
coming out of this neural net to be more closer to zero.
link |
You see here that logits are calculated
link |
as the hidden states multiplied by w2 plus b2.
link |
So first of all, currently we're initializing b2
link |
as random values of the right size.
link |
But because we want roughly zero,
link |
we don't actually want to be adding a bias
link |
of random numbers.
link |
So in fact, I'm going to add a times a zero here
link |
to make sure that b2 is just basically zero
link |
at initialization.
link |
And second, this is h multiplied by w2.
link |
So if we want logits to be very, very small,
link |
then we would be multiplying w2 and making that smaller.
link |
So for example, if we scale down w2 by 0.1,
link |
all the elements, then if I do again
link |
just the very first iteration,
link |
you see that we are getting much closer to what we expect.
link |
So roughly what we want is about 3.29.
link |
I can make this maybe even smaller, 3.32.
link |
Okay, so we're getting closer and closer.
link |
Now you're probably wondering, can we just set this to zero?
link |
Then we get, of course, exactly what we're looking for
link |
at initialization.
link |
And the reason I don't usually do this
link |
is because I'm very nervous.
link |
And I'll show you in a second
link |
why you don't wanna be setting w's
link |
or weights of a neural net exactly to zero.
link |
You usually want it to be small numbers
link |
instead of exactly zero.
link |
For this output layer in this specific case,
link |
I think it would be fine,
link |
but I'll show you in a second
link |
where things go wrong very quickly if you do that.
link |
So let's just go with 0.01.
link |
In that case, our loss is close enough,
link |
but has some entropy.
link |
It's not exactly zero.
link |
It's got some little entropy
link |
and that's used for symmetry breaking, as we'll see in a second.
link |
Logits are now coming out much closer to zero
link |
and everything is well and good.
link |
So if I just erase these
link |
and I now take away the break statement,
link |
we can run the optimization with this new initialization
link |
and let's just see what losses we record.
link |
Okay, so I'll let it run.
link |
And you see that we started off good
link |
and then we came down a bit.
link |
The plot of the loss now doesn't have
link |
this hockey shape appearance
link |
because basically what's happening in the hockey stick,
link |
the very first few iterations of the loss,
link |
what's happening during the optimization
link |
is the optimization is just squashing down the logits
link |
and then it's rearranging the logits.
link |
So basically we took away this easy part
link |
of the loss function where just the weights
link |
were just being shrunk down.
link |
And so therefore we don't get these easy gains
link |
and we're just getting some of the hard gains
link |
of training the actual neural net.
link |
And so there's no hockey stick appearance.
link |
So good things are happening in that both,
link |
number one, loss at initialization is what we expect
link |
and the loss doesn't look like a hockey stick.
link |
And this is true for any neural net you might train
link |
and something to look out for.
link |
And second, the loss that came out
link |
is actually quite a bit improved.
link |
Unfortunately, I erased what we had here before.
link |
I believe this was 2.12
link |
and this was 2.16.
link |
So we get a slightly improved result.
link |
And the reason for that is
link |
because we're spending more cycles, more time,
link |
optimizing the neural net actually,
link |
instead of just spending the first several thousand
link |
iterations probably just squashing down the weights
link |
because they are so way too high
link |
in the beginning of the initialization.
link |
So something to look out for and that's number one.
link |
Now let's look at the second problem.
link |
Let me reinitialize our neural net
link |
and let me reintroduce the break statement.
link |
So we have a reasonable initial loss.
link |
So even though everything is looking good
link |
on the level of the loss
link |
and we get something that we expect,
link |
there's still a deeper problem lurking
link |
inside this neural net and its initialization.
link |
So the logits are now okay.
link |
The problem now is with the values of H,
link |
the activations of the hidden states.
link |
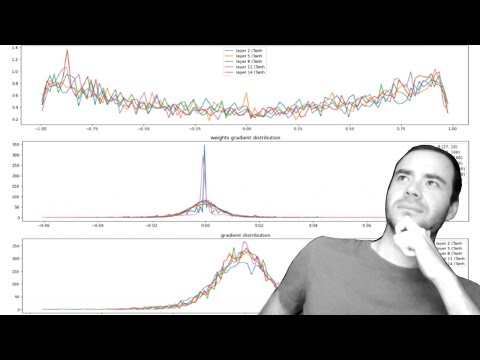
Now, if we just visualize this vector,
link |
sorry, this tensor H, it's kind of hard to see
link |
but the problem here, roughly speaking,
link |
is you see how many of the elements are one or negative one.
link |
Now recall that torch.tenh,
link |
the tenh function is a squashing function.
link |
It takes arbitrary numbers and it squashes them
link |
into a range of negative one and one
link |
and it does so smoothly.
link |
So let's look at the histogram of H
link |
to get a better idea of the distribution
link |
of the values inside this tensor.
link |
We can do this first.
link |
Well, we can see that H is 32 examples
link |
and 200 activations in each example.
link |
We can view it as negative one,
link |
stretch it out into one large vector
link |
and we can then call toList to convert this
link |
into one large Python list of floats.
link |
And then we can pass this into plt.hist for histogram
link |
and we say we want 50 bins
link |
and a semicolon to suppress a bunch of output we don't want.
link |
So we see this histogram and we see that most of the values
link |
by far take on value of negative one and one.
link |
So this tenh is very, very active.
link |
And we can also look at basically why that is.
link |
We can look at the pre-activations that feed into the tenh
link |
and we can see that the distribution of the pre-activations
link |
is very, very broad.
link |
These take numbers between negative 15 and 15
link |
and that's why in a torch.tenh,
link |
everything is being squashed and capped
link |
to be in the range of negative one and one
link |
and lots of numbers here take on very extreme values.
link |
Now, if you are new to neural networks,
link |
you might not actually see this as an issue,
link |
but if you're well versed in the dark arts
link |
of backpropagation and have an intuitive sense
link |
of how these gradients flow through a neural net,
link |
you are looking at your distribution
link |
of tenh activations here and you are sweating.
link |
So let me show you why.
link |
We have to keep in mind that during backpropagation,
link |
just like we saw in micrograd,
link |
we are doing backward pass starting at the loss
link |
and flowing through the network backwards.
link |
In particular, we're going to backpropagate
link |
through this torch.tenh.
link |
And this layer here is made up of 200 neurons
link |
for each one of these examples.
link |
And it implements an elementwise tenh.
link |
So let's look at what happens in tenh in the backward pass.
link |
We can actually go back to our previous micrograd code
link |
in the very first lecture
link |
and see how we implemented tenh.
link |
We saw that the input here was x
link |
and then we calculate t, which is the tenh of x.
link |
So that's t and t is between negative one and one.
link |
It's the output of the tenh.
link |
And then in the backward pass,
link |
how do we backpropagate through a tenh?
link |
We take out.grad and then we multiply it.
link |
This is the chain rule with the local gradient,
link |
which took the form of one minus t squared.
link |
So what happens if the outputs of your tenh
link |
are very close to negative one or one?
link |
If you plug in t equals one here,
link |
you're going to get a zero multiplying out.grad.
link |
No matter what out.grad is,
link |
we are killing the gradient
link |
and we're stopping effectively the backpropagation
link |
through this tenh unit.
link |
Similarly, when t is negative one,
link |
this will again become zero
link |
and out.grad just stops.
link |
And intuitively this makes sense
link |
because this is a tenh neuron.
link |
And what's happening is if its output is very close to one,
link |
then we are in the tail of this tenh.
link |
And so changing basically the input
link |
is not going to impact the output of the tenh too much
link |
because it's in a flat region of the tenh.
link |
And so therefore there's no impact on the loss.
link |
And so indeed the weights and the biases
link |
along with this tenh neuron do not impact the loss
link |
because the output of this tenh unit
link |
is in a flat region of the tenh
link |
and there's no influence.
link |
We can be changing them however we want
link |
and the loss is not impacted.
link |
That's another way to justify that indeed
link |
the gradient would be basically zero, it vanishes.
link |
Indeed, when t equals zero,
link |
we get one times out.grad.
link |
So when the tenh takes on exactly value of zero,
link |
then out.grad is just passed through.
link |
So basically what this is doing, right,
link |
is if t is equal to zero,
link |
then the tenh unit is sort of inactive
link |
and gradient just passes through.
link |
But the more you are in the flat tails,
link |
the more the gradient is squashed.
link |
So in fact, you'll see that the gradient
link |
flowing through tenh can only ever decrease
link |
and the amount that it decreases
link |
is proportional through a square here
link |
depending on how far you are in the flat tails
link |
And so that's kind of what's happening here.
link |
And the concern here is that if all of these outputs h
link |
are in the flat regions of negative one and one,
link |
then the gradients that are flowing through the network
link |
will just get destroyed at this layer.
link |
Now, there is some redeeming quality here
link |
and that we can actually get a sense of the problem here
link |
I wrote some code here.
link |
And basically what we want to do here
link |
is we want to take a look at h,
link |
take the absolute value and see how often it is
link |
in the flat region.
link |
So say greater than 0.99.
link |
And what you get is the following.
link |
And this is a Boolean tensor.
link |
So in the Boolean tensor, you get a white
link |
if this is true and a black if this is false.
link |
And so basically what we have here is the 32 examples
link |
and the 200 hidden neurons.
link |
And we see that a lot of this is white.
link |
And what that's telling us is that all these tenh neurons
link |
were very, very active and they're in the flat tail.
link |
And so in all these cases,
link |
the backward gradient would get destroyed.
link |
Now, we would be in a lot of trouble if,
link |
for any one of these 200 neurons,
link |
if it was the case that the entire column is white.
link |
Because in that case, we have what's called the dead neuron.
link |
And this could be a tenh neuron where the initialization
link |
of the weights and the biases could be such that
link |
no single example ever activates this tenh
link |
in the sort of active part of the tenh.
link |
If all the examples land in the tail,
link |
then this neuron will never be able to activate
link |
and this neuron will never learn.
link |
It is a dead neuron.
link |
And so just scrutinizing this and looking for columns
link |
of completely white, we see that this is not the case.
link |
So I don't see a single neuron that is all of white.
link |
And so therefore it is the case that for every one
link |
of these tenh neurons, we do have some examples
link |
that activate them in the active part of the tenh.
link |
And so some gradients will flow through
link |
and this neuron will learn.
link |
And the neuron will change and it will move
link |
and it will do something.
link |
But you can sometimes get yourself in cases
link |
where you have dead neurons.
link |
And the way this manifests is that for a tenh neuron,
link |
this would be when no matter what inputs you plug in
link |
from your data set, this tenh neuron always fires
link |
completely one or completely negative one.
link |
And then it will just not learn
link |
because all the gradients will be just zeroed out.
link |
This is true, not just for tenh,
link |
but for a lot of other nonlinearities
link |
that people use in neural networks.
link |
So we certainly use tenh a lot,
link |
but sigmoid will have the exact same issue
link |
because it is a squashing neuron.
link |
And so the same will be true for sigmoid,
link |
but basically the same will actually apply to sigmoid.
link |
The same will also apply to relu.
link |
So relu has a completely flat region here below zero.
link |
So if you have a relu neuron,
link |
then it is a pass-through if it is positive.
link |
And if the pre-activation is negative,
link |
it will just shut it off.
link |
Since the region here is completely flat,
link |
then during backpropagation,
link |
this would be exactly zeroing out the gradient.
link |
Like all of the gradient would be set exactly to zero
link |
instead of just like a very, very small number
link |
depending on how positive or negative T is.
link |
And so you can get, for example, a dead relu neuron.
link |
And a dead relu neuron would basically look like,
link |
basically what it is, is if a neuron
link |
with a relu nonlinearity never activates,
link |
so for any examples that you plug in in the dataset,
link |
it never turns on, it's always in this flat region,
link |
then this relu neuron is a dead neuron.
link |
Its weights and bias will never learn.
link |
They will never get a gradient
link |
because the neuron never activated.
link |
And this can sometimes happen at initialization
link |
because the weights and the biases just make it
link |
so that by chance, some neurons are just forever dead.
link |
But it can also happen during optimization.
link |
If you have like a too high of a learning rate, for example,
link |
sometimes you have these neurons
link |
that gets too much of a gradient
link |
and they get knocked out off the data manifold.
link |
And what happens is that from then on,
link |
no example ever activates this neuron.
link |
So this neuron remains dead forever.
link |
So it's kind of like a permanent brain damage
link |
in a mind of a network.
link |
And so sometimes what can happen is
link |
if your learning rate is very high, for example,
link |
and you have a neural net with relu neurons,
link |
you train the neural net and you get some last loss.
link |
But then actually what you do is
link |
you go through the entire training set
link |
and you forward your examples
link |
and you can find neurons that never activate.
link |
They are dead neurons in your network.
link |
And so those neurons will never turn on.
link |
And usually what happens is that during training,
link |
these relu neurons are changing, moving, et cetera.
link |
And then because of a high gradient somewhere,
link |
by chance, they get knocked off
link |
and then nothing ever activates them.
link |
And from then on, they are just dead.
link |
So that's kind of like a permanent brain damage
link |
that can happen to some of these neurons.
link |
These other nonlinearities like leaky relu
link |
will not suffer from this issue as much
link |
because you can see that it doesn't have flat tails.
link |
You'll almost always get gradients.
link |
And elu is also fairly frequently used.
link |
It also might suffer from this issue
link |
because it has flat parts.
link |
So that's just something to be aware of
link |
and something to be concerned about.
link |
And in this case, we have way too many activations H
link |
that take on extreme values.
link |
And because there's no column of white, I think we will be okay.
link |
And indeed the network optimizes
link |
and gives us a pretty decent loss,
link |
but it's just not optimal.
link |
And this is not something you want,
link |
especially during initialization.
link |
And so basically what's happening is that
link |
this H pre-activation that's flowing to 10H,
link |
it's too extreme, it's too large.
link |
It's creating a distribution that is too saturated
link |
in both sides of the 10H.
link |
And it's not something you want
link |
because it means that there's less training
link |
for these neurons because they update less frequently.
link |
So how do we fix this?
link |
Well, H pre-activation is MCAT, which comes from C.
link |
So these are uniform Gaussian,
link |
but then it's multiplied by W1 plus B1.
link |
And H pre-act is too far off from zero
link |
and that's causing the issue.
link |
So we want this pre-activation to be closer to zero,
link |
very similar to what we had with logits.
link |
So here we want actually something very, very similar.
link |
Now it's okay to set the biases to very small number.
link |
We can either multiply by 001
link |
to get like a little bit of entropy.
link |
I sometimes like to do that
link |
just so that there's like a little bit of variation
link |
and diversity in the original initialization
link |
of these 10H neurons.
link |
And I find in practice that that can help optimization
link |
And then the weights, we can also just like squash.
link |
So let's multiply everything by 0.1.
link |
Let's rerun the first batch.
link |
And now let's look at this.
link |
And well, first let's look at here.
link |
You see now, because we multiplied W by 0.1,
link |
we have a much better histogram.
link |
And that's because the pre-activations
link |
are now between negative 1.5 and 1.5.
link |
And this we expect much, much less white.
link |
Okay, there's no white.
link |
So basically that's because there are no neurons
link |
that's saturated above 0.99 in either direction.
link |
So it's actually a pretty decent place to be.
link |
Maybe we can go up a little bit.
link |
Sorry, am I changing W1 here?
link |
So maybe we can go to 0.2.
link |
Okay, so maybe something like this is a nice distribution.
link |
So maybe this is what our initialization should be.
link |
So let me now erase these.
link |
And let me, starting with initialization,
link |
let me run the full optimization without the break.
link |
And let's see what we got.
link |
Okay, so the optimization finished and I rerun the loss.
link |
And this is the result that we get.
link |
And then just as a reminder,
link |
I put down all the losses that we saw previously
link |
So we see that we actually do get an improvement here.
link |
And just as a reminder,
link |
we started off with a validation loss of 2.17
link |
By fixing the softmax being confidently wrong,
link |
we came down to 2.13.
link |
And by fixing the 10H layer being way too saturated,
link |
we came down to 2.10.
link |
And the reason this is happening, of course,
link |
is because our initialization is better.
link |
And so we're spending more time doing productive training
link |
instead of not very productive training
link |
because our gradients are set to zero.
link |
And we have to learn very simple things
link |
like the overconfidence of the softmax in the beginning.
link |
And we're spending cycles
link |
just like squashing down the weight matrix.
link |
So this is illustrating basically initialization
link |
and its impacts on performance
link |
just by being aware of the internals of these neural nets
link |
and their activations and their gradients.
link |
Now, we're working with a very small network.
link |
This is just one layer multilayer perception.
link |
So because the network is so shallow,
link |
the optimization problem is actually quite easy
link |
and very forgiving.
link |
So even though our initialization was terrible,
link |
the network still learned eventually.
link |
It just got a bit worse result.
link |
This is not the case in general, though.
link |
Once we actually start working with much deeper networks
link |
that have, say, 50 layers,
link |
things can get much more complicated
link |
and these problems stack up.
link |
And so you can actually get into a place
link |
where the network is basically not training at all
link |
if your initialization is bad enough.
link |
And the deeper your network is and the more complex it is,
link |
the less forgiving it is to some of these errors.
link |
And so something to definitely be aware of
link |
and something to scrutinize, something to plot,
link |
and something to be careful with.
link |
Okay, so that's great that that worked for us.
link |
But what we have here now is all these magic numbers,
link |
Like, where do I come up with this?
link |
And how am I supposed to set these
link |
if I have a large neural net with lots and lots of layers?
link |
And so obviously no one does this by hand.
link |
There's actually some relatively principled ways
link |
of setting these scales
link |
that I would like to introduce to you now.
link |
So let me paste some code here that I prepared
link |
just to motivate the discussion of this.
link |
So what I'm doing here is we have some random input here, x,
link |
that is drawn from a Gaussian.
link |
And there's 1,000 examples that are 10-dimensional.
link |
And then we have a weighting layer here
link |
that is also initialized using Gaussian,
link |
just like we did here.
link |
And these neurons in the hidden layer look at 10 inputs
link |
and there are 200 neurons in this hidden layer.
link |
And then we have here, just like here,
link |
in this case, the multiplication, x multiplied by w,
link |
to get the pre-activations of these neurons.
link |
And basically the analysis here looks at,
link |
okay, suppose these are uniform Gaussian
link |
and these weights are uniform Gaussian.
link |
If I do x times w, and we forget for now the bias
link |
and the nonlinearity,
link |
then what is the mean and the standard deviation
link |
of these Gaussians?
link |
So in the beginning here,
link |
the input is just a normal Gaussian distribution.
link |
Mean is zero and the standard deviation is one.
link |
And the standard deviation, again,
link |
is just a measure of a spread of the Gaussian.
link |
But then once we multiply here
link |
and we look at the histogram of y,
link |
we see that the mean, of course, stays the same.
link |
It's about zero because this is a symmetric operation.
link |
But we see here that the standard deviation
link |
has expanded to three.
link |
So the input standard deviation was one,
link |
but now we've grown to three.
link |
And so what you're seeing in the histogram
link |
is that this Gaussian is expanding.
link |
And so we're expanding this Gaussian from the input.
link |
And we don't want that.
link |
We want most of the neural nets
link |
to have relatively similar activations.
link |
So unit Gaussian roughly throughout the neural net.
link |
And so the question is,
link |
how do we scale these w's to preserve this distribution
link |
to remain a Gaussian?
link |
And so intuitively, if I multiply here,
link |
these elements of w by a large number,
link |
let's say by five, then this Gaussian
link |
grows and grows in standard deviation.
link |
So now we're at 15.
link |
So basically these numbers here in the output y
link |
take on more and more extreme values.
link |
But if we scale it down, let's say 0.2,
link |
then conversely, this Gaussian is getting smaller and smaller
link |
and it's shrinking.
link |
And you can see that the standard deviation is 0.6.
link |
And so the question is, what do I multiply by here
link |
to exactly preserve the standard deviation to be one?
link |
And it turns out that the correct answer mathematically,
link |
when you work out through the variance
link |
of this multiplication here,
link |
is that you are supposed to divide
link |
by the square root of the fan in.
link |
The fan in is basically the number
link |
of input elements here, 10.
link |
So we are supposed to divide by 10 square root.
link |
And this is one way to do the square root.
link |
You raise it to a power of 0.5.
link |
That's the same as doing a square root.
link |
So when you divide by the square root of 10,
link |
then we see that the output Gaussian,
link |
it has exactly standard deviation of 1.
link |
Now, unsurprisingly, a number of papers
link |
have looked into how to best initialize neural networks.
link |
And in the case of multi-layer perceptrons,
link |
we can have fairly deep networks that
link |
have these nonlinearities in between.
link |
And we want to make sure that the activations are
link |
well-behaved and they don't expand to infinity
link |
or shrink all the way to 0.
link |
And the question is, how do we initialize the weights
link |
so that these activations take on reasonable values
link |
throughout the network?
link |
Now, one paper that has studied this in quite a bit of detail
link |
that is often referenced is this paper by Kamingha et al.
link |
called Delving Deep Interactifiers.
link |
Now, in this case, they actually study
link |
convolutional neural networks.
link |
And they study, especially, the ReLU nonlinearity
link |
and the P-ReLU nonlinearity instead of a 10H nonlinearity.
link |
But the analysis is very similar.
link |
And basically, what happens here is, for them,
link |
the ReLU nonlinearity that they care about quite a bit here
link |
is a squashing function where all the negative numbers
link |
are simply clamped to 0.
link |
So the positive numbers are a path through,
link |
but everything negative is just set to 0.
link |
And because you are basically throwing away
link |
half of the distribution, they find in their analysis
link |
of the forward activations in the neural net
link |
that you have to compensate for that with a gain.
link |
And so here, they find that, basically,
link |
when they initialize their weights,
link |
they have to do it with a zero-mean Gaussian
link |
whose standard deviation is square root of 2 over the Fannin.
link |
What we have here is we are initializing the Gaussian
link |
with the square root of Fannin.
link |
This NL here is the Fannin.
link |
So what we have is square root of 1 over the Fannin
link |
because we have the division here.
link |
Now, they have to add this factor of 2
link |
because of the ReLU, which basically discards
link |
half of the distribution and clamps it at 0.
link |
And so that's where you get an initial factor.
link |
Now, in addition to that, this paper also studies
link |
not just the behavior of the activations
link |
in the forward pass of the neural net,
link |
but it also studies the backpropagation.
link |
And we have to make sure that the gradients also
link |
are well-behaved because ultimately, they
link |
end up updating our parameters.
link |
And what they find here through a lot of the analysis
link |
that I invite you to read through, but it's not exactly
link |
approachable, what they find is basically
link |
if you properly initialize the forward pass,
link |
the backward pass is also approximately initialized
link |
up to a constant factor that has to do
link |
with the size of the number of hidden neurons
link |
in an early and late layer.
link |
But basically, they find empirically
link |
that this is not a choice that matters too much.
link |
Now, this kind of initialization is also
link |
implemented in PyTorch.
link |
So if you go to torch.nn.init documentation,
link |
you'll find climbing normal.
link |
And in my opinion, this is probably
link |
the most common way of initializing neural networks
link |
And it takes a few keyword arguments here.
link |
So number one, it wants to know the mode.
link |
Would you like to normalize the activations,
link |
or would you like to normalize the gradients to be always
link |
Gaussian with zero mean and a unit or one standard deviation?
link |
And because they find in the paper
link |
that this doesn't matter too much,
link |
most of the people just leave it as the default, which
link |
And then second, pass in the nonlinearity
link |
that you are using.
link |
Because depending on the nonlinearity,
link |
we need to calculate a slightly different gain.
link |
And so if your nonlinearity is just linear,
link |
so there's no nonlinearity, then the gain here will be 1.
link |
And we have the exact same kind of formula
link |
that we've got up here.
link |
But if the nonlinearity is something else,
link |
we're going to get a slightly different gain.
link |
And so if we come up here to the top,
link |
we see that, for example, in the case of ReLU,
link |
this gain is a square root of 2.
link |
And the reason it's a square root,
link |
because in this paper, you see how the 2 is inside
link |
of the square root, so the gain is a square root of 2.
link |
In the case of linear or identity,
link |
we just get a gain of 1.
link |
In the case of 10H, which is what we're using here,
link |
the advised gain is a 5 over 3.
link |
And intuitively, why do we need a gain
link |
on top of the initialization?
link |
It's because 10H, just like ReLU,
link |
is a contractive transformation.
link |
So what that means is you're taking the output distribution
link |
from this matrix multiplication,
link |
and then you are squashing it in some way.
link |
Now, ReLU squashes it by taking everything below 0
link |
and clamping it to 0.
link |
10H also squashes it because it's a contractive operation.
link |
It will take the tails, and it will squeeze them in.
link |
And so in order to fight the squeezing in,
link |
we need to boost the weights a little bit
link |
so that we renormalize everything back
link |
to unit standard deviation.
link |
So that's why there's a little bit of a gain that comes out.
link |
Now, I'm skipping through this section a little bit quickly,
link |
and I'm doing that actually intentionally.
link |
And the reason for that is because about seven years ago,
link |
when this paper was written, you had to actually be extremely
link |
careful with the activations and the gradients
link |
and their ranges and their histograms.
link |
And you had to be very careful with the precise setting
link |
of gains and the scrutinizing of the nonlinearities used
link |
And everything was very finicky and very frustrating.
link |
And it had to be very properly arranged for the neural net
link |
to train, especially if your neural net was very deep.
link |
But there are a number of modern innovations
link |
that have made everything significantly more stable
link |
and more well-behaved.
link |
And it's become less important to initialize these networks
link |
And some of those modern innovations, for example,
link |
are residual connections, which we will cover in the future,
link |
the use of a number of normalization layers,
link |
like, for example, batch normalization,
link |
layer normalization, group normalization.
link |
We're going to go into a lot of these as well.
link |
And number three, much better optimizers,
link |
not just to cast a gradient descent,
link |
the simple optimizer we're basically using here,
link |
but slightly more complex optimizers,
link |
like RMSProp and especially Adam.
link |
And so all of these modern innovations
link |
make it less important for you to precisely calibrate
link |
the initialization of the neural net.
link |
All that being said, in practice, what should we do?
link |
In practice, when I initialize these neural nets,
link |
I basically just normalize my weights
link |
by the square root of the fan in.
link |
So basically, roughly what we did here is what I do.
link |
Now, if we want to be exactly accurate here,
link |
and go back in it of kind of normal,
link |
this is how we would implement it.
link |
We want to set the standard deviation
link |
to be gain over the square root of fan in.
link |
So to set the standard deviation of our weights,
link |
we will proceed as follows.
link |
Basically, when we have a torsade random,
link |
and let's say I just create a thousand numbers,
link |
we can look at the standard deviation of this,
link |
and of course, that's one, that's the amount of spread.
link |
Let's make this a bit bigger so it's closer to one.
link |
So this is the spread of the Gaussian of zero mean
link |
and unit standard deviation.
link |
Now, basically, when you take these
link |
and you multiply by, say, 0.2,
link |
that basically scales down the Gaussian,
link |
and that makes its standard deviation 0.2.
link |
So basically, the number that you multiply by here
link |
ends up being the standard deviation of this Gaussian.
link |
So here, this is a standard deviation 0.2 Gaussian here
link |
when we sample Rw1.
link |
But we want to set the standard deviation
link |
to gain over square root of fan load, which is fan in.
link |
So in other words, we want to multiply by gain,
link |
which for 10h is five over three.
link |
Five over three is the gain.
link |
And then divide square root of the fan in.
link |
And in this example here, the fan in was 10.
link |
And I just noticed that actually here,
link |
the fan in for W1 is actually an embed times block size,
link |
which as you will recall is actually 30.
link |
And that's because each character is 10-dimensional,
link |
but then we have three of them and we concatenate them.
link |
So actually, the fan in here was 30,
link |
and I should have used 30 here probably.
link |
But basically, we want 30 square root.
link |
So this is the number.
link |
This is what our standard deviation we want to be.
link |
And this number turns out to be 0.3.
link |
Whereas here, just by fiddling with it
link |
and looking at the distribution and making sure it looks OK,
link |
we came up with 0.2.
link |
And so instead, what we want to do here
link |
is we want to make the standard deviation be
link |
5 over 3, which is our gain.
link |
Divide this amount times 0.2 square root.
link |
And these brackets here are not that necessary,
link |
but I'll just put them here for clarity.
link |
This is basically what we want.
link |
This is the Kaiming init in our case for a 10H nonlinearity.
link |
And this is how we would initialize the neural net.
link |
And so we're multiplying by 0.3 instead of multiplying by 0.2.
link |
And so we can initialize this way.
link |
And then we can train the neural net and see what we get.
link |
OK, so I trained the neural net, and we end up
link |
in roughly the same spot.
link |
So looking at the validation loss, we now get 2.10.
link |
And previously, we also had 2.10.
link |
There's a little bit of a difference,
link |
but that's just the randomness of the process, I suspect.
link |
But the big deal, of course, is we get to the same spot.
link |
But we did not have to introduce any magic numbers
link |
that we got from just looking at histograms and guess
link |
We have something that is semi-principled
link |
and will scale us to much bigger networks and something
link |
that we can use as a guide.
link |
So I mentioned that the precise setting of these initializations
link |
is not as important today due to some modern innovations.
link |
And I think now is a pretty good time
link |
to introduce one of those modern innovations,
link |
and that is batch normalization.
link |
So batch normalization came out in 2015 from a team at Google.
link |
And it was an extremely impactful paper
link |
because it made it possible to train very deep neural nets
link |
And it basically just worked.
link |
So here's what batch normalization does,
link |
and let's implement it.
link |
Basically, we have these hidden states hpreact, right?
link |
And we were talking about how we don't
link |
want these pre-activation states to be way too small
link |
because then the 10h is not doing anything.
link |
But we don't want them to be too large because then
link |
the 10h is saturated.
link |
In fact, we want them to be roughly Gaussian,
link |
so zero mean and a unit or one standard deviation,
link |
at least at initialization.
link |
So the insight from the batch normalization paper
link |
is, OK, you have these hidden states,
link |
and you'd like them to be roughly Gaussian.
link |
Then why not take the hidden states
link |
and just normalize them to be Gaussian?
link |
And it sounds kind of crazy, but you can just
link |
do that because standardizing hidden states
link |
so that they're Gaussian is a perfectly differentiable
link |
operation, as we'll soon see.
link |
And so that was kind of like the big insight in this paper.
link |
And when I first read it, my mind
link |
was blown because you can just normalize these hidden states.
link |
And if you'd like unit Gaussian states in your network,
link |
at least initialization, you can just normalize
link |
them to be unit Gaussian.
link |
So let's see how that works.
link |
So we're going to scroll to our pre-activations here
link |
just before they enter into the 10h.
link |
Now, the idea, again, is remember,
link |
we're trying to make these roughly Gaussian.
link |
And that's because if these are way too small numbers,
link |
then the 10h here is kind of inactive.
link |
But if these are very large numbers,
link |
then the 10h is way too saturated
link |
and gradient is no flow.
link |
So we'd like this to be roughly Gaussian.
link |
So the insight in batch normalization, again,
link |
is that we can just standardize these activations
link |
so they are exactly Gaussian.
link |
So here, hpreact has a shape of 32 by 200,
link |
32 examples by 200 neurons in the hidden layer.
link |
So basically what we can do is we can take hpreact
link |
and we can just calculate the mean.
link |
And the mean we want to calculate
link |
across the 0th dimension.
link |
And we want to also keep them as true
link |
so that we can easily broadcast this.
link |
So the shape of this is 1 by 200.
link |
In other words, we are doing the mean over all
link |
the elements in the batch.
link |
And similarly, we can calculate the standard deviation
link |
of these activations.
link |
And that will also be 1 by 200.
link |
Now in this paper, they have the sort of prescription here.
link |
And see here, we are calculating the mean,
link |
which is just taking the average value of any neuron's
link |
And then the standard deviation is basically
link |
kind of like the measure of the spread
link |
that we've been using, which is the distance of every one
link |
of these values away from the mean,
link |
and that squared and averaged.
link |
That's the variance.
link |
And then if you want to take the standard deviation,
link |
you would square root the variance
link |
to get the standard deviation.
link |
So these are the two that we're calculating.
link |
And now we're going to normalize or standardize
link |
these x's by subtracting the mean
link |
and dividing by the standard deviation.
link |
So basically, we're taking edge preact,
link |
and we subtract the mean, and then we
link |
divide by the standard deviation.
link |
This is exactly what these two, STD and mean, are calculating.
link |
This is the mean, and this is the variance.
link |
You see how the sigma is the standard deviation usually.
link |
So this is sigma squared, which the variance
link |
is the square of the standard deviation.
link |
So this is how you standardize these values.
link |
And what this will do is that every single neuron now
link |
and its firing rate will be exactly unit Gaussian
link |
on these 32 examples, at least, of this batch.
link |
That's why it's called batch normalization.
link |
We are normalizing these batches.
link |
And then we could, in principle, train this.
link |
Notice that calculating the mean and the standard deviation,
link |
these are just mathematical formulas.
link |
They're perfectly differentiable.
link |
All this is perfectly differentiable,
link |
and we can just train this.
link |
The problem is you actually won't achieve a very good
link |
And the reason for that is we want
link |
these to be roughly Gaussian, but only at initialization.
link |
But we don't want these to be forced to be Gaussian always.
link |
We'd like to allow the neural net to move this around
link |
to potentially make it more diffuse, to make it more sharp,
link |
to make some 10-H neurons maybe be more trigger happy
link |
or less trigger happy.
link |
So we'd like this distribution to move around,
link |
and we'd like the backpropagation
link |
to tell us how the distribution should move around.
link |
And so in addition to this idea of standardizing
link |
the activations at any point in the network,
link |
we have to also introduce this additional component
link |
in the paper here described as scale and shift.
link |
And so basically what we're doing is we're
link |
taking these normalized inputs, and we are additionally
link |
scaling them by some gain and offsetting them by some bias
link |
to get our final output from this layer.
link |
And so what that amounts to is the following.
link |
We are going to allow a batch normalization gain
link |
to be initialized at just a 1s, and the 1s
link |
will be in the shape of 1 by n hidden.
link |
And then we also will have a bn bias,
link |
which will be torched at 0s, and it will also
link |
be of the shape 1 by n hidden.
link |
And then here, the bn gain will multiply this,
link |
and the bn bias will offset it here.
link |
So because this is initialized to 1 and this to 0,
link |
at initialization, each neuron's firing values in this batch
link |
will be exactly unit Gaussian, and will have nice numbers.
link |
No matter what the distribution of the HP act is coming in,
link |
coming out, it will be unit Gaussian for each neuron,
link |
and that's roughly what we want, at least at initialization.
link |
And then during optimization, we'll
link |
be able to backpropagate to bn gain and bn bias
link |
and change them so the network is given the full ability
link |
to do with this whatever it wants internally.
link |
Here, we just have to make sure that we include
link |
these in the parameters of the neural net
link |
because they will be trained with backpropagation.
link |
So let's initialize this, and then we
link |
should be able to train.
link |
And then we're going to also copy this line, which
link |
is the batch normalization layer,
link |
here on a single line of code, and we're
link |
going to swing down here, and we're also
link |
going to do the exact same thing at test time here.
link |
So similar to train time, we're going to normalize and then
link |
scale, and that's going to give us our train and validation
link |
And we'll see in a second that we're actually
link |
going to change this a little bit, but for now,
link |
I'm going to keep it this way.
link |
So I'm just going to wait for this to converge.
link |
OK, so I allowed the neural nets to converge here,
link |
and when we scroll down, we see that our validation loss here
link |
is 2.10, roughly, which I wrote down here.
link |
And we see that this is actually kind of comparable to some
link |
of the results that we've achieved previously.
link |
Now, I'm not actually expecting an improvement in this case,
link |
and that's because we are dealing
link |
with a very simple neural net that has just
link |
a single hidden layer.
link |
So in fact, in this very simple case of just one hidden layer,
link |
we were able to actually calculate
link |
what the scale of W should be to make these pre-activations
link |
already have a roughly Gaussian shape.
link |
So the batch normalization is not doing much here.
link |
But you might imagine that once you
link |
have a much deeper neural net that
link |
has lots of different types of operations,
link |
and there's also, for example, residual connections,
link |
which we'll cover, and so on, it will become basically very,
link |
very difficult to tune the scales of your weight matrices
link |
such that all the activations throughout the neural net
link |
are roughly Gaussian.
link |
And so that's going to become very quickly intractable.
link |
But compared to that, it's going to be much, much easier
link |
to sprinkle batch normalization layers
link |
throughout the neural net.
link |
So in particular, it's common to look
link |
at every single linear layer like this one.
link |
This is a linear layer multiplying by a weight matrix
link |
and adding a bias.
link |
Or, for example, convolutions, which we'll cover later,
link |
and also perform basically a multiplication
link |
with a weight matrix, but in a more spatially structured
link |
format, it's customary to take these linear layer
link |
or convolutional layer and append a batch normalization
link |
layer right after it to control the scale
link |
of these activations at every point in the neural net.
link |
So we'd be adding these batch normal layers
link |
throughout the neural net, and then
link |
this controls the scale of these activations
link |
throughout the neural net.
link |
It doesn't require us to do perfect mathematics
link |
and care about the activation distributions
link |
for all these different types of neural network
link |
Lego building blocks that you might want to introduce
link |
into your neural net.
link |
And it significantly stabilizes the train,
link |
and that's why these layers are quite popular.
link |
Now, the stability offered by batch normalization
link |
actually comes at a terrible cost.
link |
And that cost is that if you think
link |
about what's happening here, something terribly strange
link |
and unnatural is happening.
link |
It used to be that we have a single example feeding
link |
into a neural net, and then we calculate its activations
link |
And this is a deterministic process,
link |
so you arrive at some logits for this example.
link |
And then because of efficiency of training,
link |
we suddenly started to use batches of examples.
link |
But those batches of examples were processed independently,
link |
and it was just an efficiency thing.
link |
But now suddenly, in batch normalization,
link |
because of the normalization through the batch,
link |
we are coupling these examples mathematically
link |
and in the forward pass and the backward pass of a neural net.
link |
So now, the hidden state activations,
link |
hpreact and your logits for any one input example
link |
are not just a function of that example and its input,
link |
but they're also a function of all the other examples that
link |
happen to come for a ride in that batch.
link |
And these examples are sampled randomly.
link |
And so what's happening is, for example,
link |
when you look at hpreact that's going to feed into h,
link |
the hidden state activations, for example,
link |
for any one of these input examples,
link |
is going to actually change slightly,
link |
depending on what other examples there are in the batch.
link |
And depending on what other examples
link |
happen to come for a ride, h is going to change suddenly,
link |
and it's going to jitter, if you imagine
link |
sampling different examples.
link |
Because the statistics of the mean and the standard deviation
link |
are going to be impacted.
link |
And so you'll get a jitter for h,
link |
and you'll get a jitter for logits.
link |
And you'd think that this would be a bug or something
link |
But in a very strange way, this actually
link |
turns out to be good in neural network training
link |
And the reason for that is that you
link |
can think of this as kind of like a regularizer.
link |
Because what's happening is you have your input,
link |
and you get your h.
link |
And then depending on the other examples,
link |
this is jittering a bit.
link |
And so what that does is that it's effectively padding out
link |
any one of these input examples.
link |
And it's introducing a little bit of entropy.
link |
And because of the padding out, it's
link |
actually kind of like a form of a data augmentation, which
link |
we'll cover in the future.
link |
And it's kind of like augmenting the input a little bit,
link |
and it's jittering it.
link |
And that makes it harder for the neural net
link |
to overfit these concrete specific examples.
link |
So by introducing all this noise,
link |
it actually like pads out the examples,
link |
and it regularizes the neural net.
link |
And that's one of the reasons why, deceivingly,
link |
as a second-order effect, this is actually a regularizer.
link |
And that has made it harder for us
link |
to remove the use of batch normalization.
link |
Because basically, no one likes this property that the examples
link |
in the batch are coupled mathematically
link |
and in the forward pass.
link |
And it leads to all kinds of strange results.
link |
We'll go into some of that in a second as well.
link |
And it leads to a lot of bugs and so on.
link |
And so no one likes this property.
link |
And so people have tried to deprecate
link |
the use of batch normalization and move to other normalization
link |
techniques that do not couple the examples of a batch.
link |
Examples are linear normalization,
link |
instance normalization, group normalization, and so on.
link |
And we'll cover some of these later.
link |
But basically, long story short, batch normalization
link |
was the first kind of normalization layer
link |
It worked extremely well.
link |
It happened to have this regularizing effect.
link |
It stabilized training.
link |
And people have been trying to remove it and move
link |
to some of the other normalization techniques.
link |
But it's been hard because it just works quite well.
link |
And some of the reason that it works quite well
link |
is, again, because of this regularizing effect
link |
and because it is quite effective at controlling
link |
the activations and their distributions.
link |
So that's kind of like the brief story of batch normalization.
link |
And I'd like to show you one of the other weird sort
link |
of outcomes of this coupling.
link |
So here's one of the strange outcomes
link |
that I only glossed over previously
link |
when I was evaluating the loss on the validation set.
link |
Basically, once we've trained a neural net,
link |
we'd like to deploy it in some kind of a setting.
link |
And we'd like to be able to feed in a single individual
link |
example and get a prediction out from our neural net.
link |
But how do we do that when our neural net now
link |
in the forward pass estimates the statistics
link |
of the mean and standard deviation of a batch?
link |
The neural net expects batches as an input now.
link |
So how do we feed in a single example
link |
and get sensible results out?
link |
And so the proposal in the batch normalization paper
link |
What we would like to do here is we
link |
would like to basically have a step after training that
link |
calculates and sets the batch norm mean and standard
link |
deviation a single time over the training set.
link |
And so I wrote this code here in interest of time.
link |
And we're going to call what's called calibrate
link |
the batch norm statistics.
link |
And basically, what we do is torsnot no grad,
link |
telling PyTorch that none of this
link |
we will call the dot backward on.
link |
And it's going to be a bit more efficient.
link |
We're going to take the training set,
link |
get the preactivations for every single training example,
link |
and then one single time estimate the mean and standard
link |
deviation over the entire training set.
link |
And then we're going to get bn mean and bn standard deviation.
link |
And now these are fixed numbers estimated
link |
over the entire training set.
link |
And here, instead of estimating it dynamically,
link |
we are going to instead here use bn mean.
link |
And here, we're just going to use bn standard deviation.
link |
And so at test time, we are going
link |
to fix these, clamp them, and use them during inference.
link |
And now you see that we get basically identical result.
link |
But the benefit that we've gained
link |
is that we can now also forward a single example
link |
because the mean and standard deviation are now fixed
link |
That said, nobody actually wants to estimate
link |
this mean and standard deviation as a second stage
link |
after neural network training because everyone is lazy.
link |
And so this batch normalization paper
link |
actually introduced one more idea,
link |
which is that we can estimate the mean and standard
link |
deviation in a running manner during training
link |
of the neural net.
link |
And then we can simply just have a single stage of training.
link |
And on the side of that training,
link |
we are estimating the running mean and standard deviation.
link |
So let's see what that would look like.
link |
Let me basically take the mean here
link |
that we are estimating on the batch.
link |
And let me call this bn mean on the ith iteration.
link |
And then here, this is bn std at i.
link |
And the mean comes here, and the std comes here.
link |
So so far, I've done nothing.
link |
I've just moved around, and I created these extra variables
link |
for the mean and standard deviation.
link |
And I've put them here.
link |
So so far, nothing has changed.
link |
But what we're going to do now is
link |
we're going to keep a running mean of both of these values
link |
So let me swing up here.
link |
And let me create a bn mean underscore running.
link |
And I'm going to initialize it at zeros.
link |
And then bn std running, which I'll initialize at once.
link |
Because in the beginning, because of the way
link |
we initialized w1 and b1, each preact
link |
will be roughly unit Gaussian.
link |
So the mean will be roughly 0, and the standard deviation
link |
So I'm going to initialize these that way.
link |
But then here, I'm going to update these.
link |
And in PyTorch, these mean and standard deviation
link |
that are running, they're not actually
link |
part of the gradient-based optimization.
link |
We're never going to derive gradients with respect to them.
link |
They're updated on the side of training.
link |
And so what we're going to do here
link |
is we're going to say with torch.nograd telling PyTorch
link |
that the update here is not supposed
link |
to be building out a graph, because there
link |
will be no dot backward.
link |
But this running mean is basically
link |
going to be 0.999 times the current value
link |
plus 0.001 times this value, this new mean.
link |
And in the same way, bn std running
link |
will be mostly what it used to be.
link |
But it will receive a small update
link |
in the direction of what the current standard deviation is.
link |
And as you're seeing here, this update
link |
is outside and on the side of the gradient-based optimization.
link |
And it's simply being updated not using gradient descent.
link |
It's just being updated using a janky, smooth running mean
link |
And so while the network is training,
link |
and these pre-activations are sort of changing and shifting
link |
around during backpropagation, we
link |
are keeping track of the typical mean and standard deviation,
link |
and we're estimating them once.
link |
And when I run this, now I'm keeping track
link |
of this in the running matter.
link |
And what we're hoping for, of course,
link |
is that the bn mean underscore running and bn mean underscore
link |
std are going to be very similar to the ones that we calculated
link |
And that way, we don't need a second stage, because we've
link |
sort of combined the two stages, and we've
link |
put them on the side of each other,
link |
if you want to look at it that way.
link |
And this is how this is also implemented
link |
in the batch normalization layer in PyTorch.
link |
So during training, the exact same thing will happen.
link |
And then later, when you're using inference,
link |
it will use the estimated running
link |
mean of both the mean and standard deviation
link |
of those hidden states.
link |
So let's wait for the optimization
link |
to complete, and then we'll go ahead
link |
and let's wait for the optimization to converge.
link |
And hopefully, the running mean and standard deviation
link |
are roughly equal to these two.
link |
And then we can simply use it here.
link |
And we don't need this stage of explicit calibration
link |
OK, so the optimization finished.
link |
I'll rerun the explicit estimation.
link |
And then the bn mean from the explicit estimation is here.
link |
And bn mean from the running estimation
link |
during the optimization you can see is very, very similar.
link |
It's not identical, but it's pretty close.
link |
And in the same way, bnstd is this.
link |
And bnstd running is this.
link |
As you can see that, once again, they are fairly similar values.
link |
Not identical, but pretty close.
link |
And so then here, instead of bn mean,
link |
we can use the bn mean running.
link |
Instead of bnstd, we can use bnstd running.
link |
And hopefully, the validation loss
link |
will not be impacted too much.
link |
OK, so it's basically identical.
link |
And this way, we've eliminated the need
link |
for this explicit stage of calibration
link |
because we are doing it inline over here.
link |
OK, so we're almost done with batch normalization.
link |
There are only two more notes that I'd like to make.
link |
Number one, I've skipped a discussion
link |
over what is this plus epsilon doing here.
link |
This epsilon is usually like some small fixed number.
link |
For example, 1e negative 5 by default.
link |
And what it's doing is that it's basically
link |
preventing a division by 0.
link |
In the case that the variance over your batch
link |
In that case, here, we normally have a division by 0.
link |
But because of the plus epsilon, this
link |
is going to become a small number in the denominator
link |
And things will be more well-behaved.
link |
So feel free to also add a plus epsilon here
link |
of a very small number.
link |
It doesn't actually substantially change the result.
link |
I'm going to skip it in our case just
link |
because this is unlikely to happen
link |
in our very simple example here.
link |
And the second thing I want you to notice
link |
is that we're being wasteful here.
link |
And it's very subtle.
link |
But right here, where we are adding
link |
the bias into H preact, these biases now
link |
are actually useless because we're adding them
link |
But then we are calculating the mean
link |
for every one of these neurons and subtracting it.
link |
So whatever bias you add here is going
link |
to get subtracted right here.
link |
And so these biases are not doing anything.
link |
In fact, they're being subtracted out.
link |
And they don't impact the rest of the calculation.
link |
So if you look at B1.grad, it's actually
link |
going to be 0 because it's being subtracted out
link |
and doesn't actually have any effect.
link |
And so whenever you're using batch normalization layers,
link |
then if you have any weight layers before,
link |
like a linear or a comb or something like that,
link |
you're better off coming here and just not using bias.
link |
So you don't want to use bias.
link |
And then here, you don't want to add it
link |
because it's that spurious.
link |
Instead, we have this batch normalization bias here.
link |
And that batch normalization bias
link |
is now in charge of the biasing of this distribution
link |
instead of this B1 that we had here originally.
link |
And so basically, the batch normalization layer
link |
And there's no need to have a bias in the layer
link |
before it because that bias is going
link |
to be subtracted out anyway.
link |
So that's the other small detail to be careful with sometimes.
link |
It's not going to do anything catastrophic.
link |
This B1 will just be useless.
link |
It will never get any gradient.
link |
It will not learn.
link |
It will stay constant.
link |
And it's just wasteful.
link |
But it doesn't actually really impact anything otherwise.
link |
OK, so I rearranged the code a little bit with comments.
link |
And I just wanted to give a very quick summary
link |
of the batch normalization layer.
link |
We are using batch normalization to control
link |
the statistics of activations in the neural net.
link |
It is common to sprinkle batch normalization
link |
layer across the neural net.
link |
And usually, we will place it after layers
link |
that have multiplications, like, for example,
link |
a linear layer or a convolutional layer,
link |
which we may cover in the future.
link |
Now, the batch normalization internally has parameters
link |
for the gain and the bias.
link |
And these are trained using backpropagation.
link |
It also has two buffers.
link |
The buffers are the mean and the standard deviation,
link |
the running mean and the running mean of the standard deviation.
link |
And these are not trained using backpropagation.
link |
These are trained using this janky update of kind
link |
of like a running mean update.
link |
So these are sort of the parameters and the buffers
link |
of batch normalization.
link |
And then really what it's doing is
link |
it's calculating the mean and the standard deviation
link |
of the activations that are feeding into the batch normalization
link |
Then it's centering that batch to be unit Gaussian.
link |
And then it's offsetting and scaling it
link |
by the learned bias and gain.
link |
And then on top of that, it's keeping
link |
track of the mean and standard deviation of the inputs.
link |
And it's maintaining this running mean and standard
link |
And this will later be used at inference
link |
so that we don't have to re-estimate the mean
link |
and standard deviation all the time.
link |
And in addition, that allows us to basically forward
link |
individual examples at test time.
link |
So that's the batch normalization layer.
link |
It's a fairly complicated layer.
link |
But this is what it's doing internally.
link |
Now, I wanted to show you a little bit of a real example.
link |
So you can search ResNet, which is a residual neural network.
link |
And these are context of neural networks
link |
used for image classification.
link |
And of course, we haven't come to ResNets in detail.
link |
So I'm not going to explain all the pieces of it.
link |
But for now, just note that the image feeds into a ResNet
link |
And there's many, many layers with repeating structure
link |
all the way to predictions of what's inside that image.
link |
This repeating structure is made up of these blocks.
link |
And these blocks are just sequentially stacked up
link |
in this deep neural network.
link |
Now, the code for this, the block basically that's used
link |
and repeated sequentially in series,
link |
is called this bottleneck block.
link |
And there's a lot here.
link |
This is all PyTorch.
link |
And of course, we haven't covered all of it.
link |
But I want to point out some small pieces of it.
link |
Here in the init is where we initialize the neural net.
link |
So this code of block here is basically the kind of stuff
link |
We're initializing all the layers.
link |
And in the forward, we are specifying
link |
how the neural net acts once you actually have the input.
link |
So this code here is along the lines
link |
of what we're doing here.
link |
And now these blocks are replicated and stacked up
link |
And that's what a residual network would be.
link |
And so notice what's happening here.
link |
Conv1, these are convolutional layers.
link |
And these convolutional layers, basically,
link |
they're the same thing as a linear layer,
link |
except convolutional layers don't
link |
apply convolutional layers are used for images.
link |
And so they have spatial structure.
link |
And basically, this linear multiplication and bias offset
link |
are done on patches instead of the full input.
link |
So because these images have structure, spatial structure,
link |
convolutions just basically do wx plus b.
link |
But they do it on overlapping patches of the input.
link |
But otherwise, it's wx plus b.
link |
Then we have the norm layer, which by default
link |
here is initialized to be a batch norm in 2D,
link |
so two-dimensional batch normalization layer.
link |
And then we have a nonlinearity like ReLU.
link |
So instead of here they use ReLU,
link |
we are using 10H in this case.
link |
But both are just nonlinearities,
link |
and you can just use them relatively interchangeably.
link |
For very deep networks, ReLUs typically empirically
link |
work a bit better.
link |
So see the motif that's being repeated here.
link |
We have convolution, batch normalization, ReLU.
link |
Convolution, batch normalization, ReLU, et cetera.
link |
And then here, this is a residual connection
link |
that we haven't covered yet.
link |
But basically, that's the exact same pattern we have here.
link |
We have a weight layer, like a convolution
link |
or like a linear layer, batch normalization,
link |
and then 10H, which is a nonlinearity.
link |
But basically, a weight layer, a normalization layer,
link |
And that's the motif that you would be stacking up
link |
when you create these deep neural networks, exactly
link |
And one more thing I'd like you to notice
link |
is that here, when they are initializing the conv layers,
link |
like conv one by one, the depth for that is right here.
link |
And so it's initializing an nn.conf2d,
link |
which is a convolution layer in PyTorch.
link |
And there's a bunch of keyword arguments here
link |
that I'm not going to explain yet.
link |
But you see how there's bias equals false.
link |
The bias equals false is exactly for the same reason
link |
as bias is not used in our case.
link |
You see how I erase the use of bias.
link |
And the use of bias is spurious, because after this weight
link |
layer, there's a bastion normalization.
link |
And the bastion normalization subtracts that bias
link |
and then has its own bias.
link |
So there's no need to introduce these spurious parameters.
link |
It wouldn't hurt performance, it's just useless.
link |
And so because they have this motif of conv bastion
link |
and relu, they don't need a bias here,
link |
because there's a bias inside here.
link |
So by the way, this example here is very easy to find.
link |
Just do a resnet PyTorch, and it's this example here.
link |
So this is kind of like the stock implementation
link |
of a residual neural network in PyTorch.
link |
And you can find that here.
link |
But of course, I haven't covered many of these parts yet.
link |
And I would also like to briefly descend
link |
into the definitions of these PyTorch layers
link |
and the parameters that they take.
link |
Now, instead of a convolutional layer,
link |
we're going to look at a linear layer,
link |
because that's the one that we're using here.
link |
This is a linear layer, and I haven't covered convolutions
link |
But as I mentioned, convolutions are basically linear layers
link |
except on patches.
link |
So a linear layer performs a wx plus b,
link |
except here they're calling the wa transpose.
link |
So it's called wx plus b, very much like we did here.
link |
To initialize this layer, you need
link |
to know the fan in, the fan out.
link |
And that's so that they can initialize this w.
link |
This is the fan in and the fan out.
link |
So they know how big the weight matrix should be.
link |
You need to also pass in whether or not you want a bias.
link |
And if you set it to false, then no bias
link |
will be inside this layer.
link |
And you may want to do that exactly like in our case,
link |
if your layer is followed by a normalization
link |
layer such as batch norm.
link |
So this allows you to basically disable bias.
link |
Now, in terms of the initialization,
link |
if we swing down here, this is reporting the variables used
link |
inside this linear layer.
link |
And our linear layer here has two parameters, the weight
link |
In the same way, they have a weight and a bias.
link |
And they're talking about how they initialize it by default.
link |
So by default, PyTorch will initialize your weights
link |
by taking the fan in and then doing 1 over fan in square
link |
And then instead of a normal distribution,
link |
they are using a uniform distribution.
link |
So it's very much the same thing.
link |
But they are using a 1 instead of 5 over 3.
link |
So there's no gain being calculated here.
link |
The gain is just 1.
link |
But otherwise, it's exactly 1 over the square root of fan in
link |
exactly as we have here.
link |
So 1 over the square root of k is the scale of the weights.
link |
But when they are drawing the numbers,
link |
they're not using a Gaussian by default.
link |
They're using a uniform distribution by default.
link |
And so they draw uniformly from negative square root of k
link |
to square root of k.
link |
But it's the exact same thing and the same motivation
link |
with respect to what we've seen in this lecture.
link |
And the reason they're doing this is,
link |
if you have a roughly Gaussian input,
link |
this will ensure that out of this layer,
link |
you will have a roughly Gaussian output.
link |
And you basically achieve that by scaling the weights
link |
by 1 over the square root of fan in.
link |
So that's what this is doing.
link |
And then the second thing is the batch normalization layer.
link |
So let's look at what that looks like in PyTorch.
link |
So here we have a one-dimensional batch
link |
normalization layer exactly as we are using here.
link |
And there are a number of keyword arguments going into it
link |
So we need to know the number of features.
link |
For us, that is 200.
link |
And that is needed so that we can initialize
link |
these parameters here, the gain, the bias,
link |
and the buffers for the running mean and standard deviation.
link |
Then they need to know the value of epsilon here.
link |
And by default, this is 1 negative 5.
link |
You don't typically change this too much.
link |
Then they need to know the momentum.
link |
And the momentum here, as they explain,
link |
is basically used for these running mean and running
link |
standard deviation.
link |
So by default, the momentum here is 0.1.
link |
The momentum we are using here in this example is 0.001.
link |
And basically, you may want to change this sometimes.
link |
And roughly speaking, if you have a very large batch size,
link |
then typically what you'll see is
link |
that when you estimate the mean and the standard deviation,
link |
for every single batch size, if it's large enough,
link |
you're going to get roughly the same result.
link |
And so therefore, you can use slightly higher momentum,
link |
But for a batch size as small as 32,
link |
the mean and standard deviation here
link |
might take on slightly different numbers,
link |
because there's only 32 examples we
link |
are using to estimate the mean and standard deviation.
link |
So the value is changing around a lot.
link |
And if your momentum is 0.1, that
link |
might not be good enough for this value
link |
to settle and converge to the actual mean and standard
link |
deviation over the entire training set.
link |
And so basically, if your batch size is very small,
link |
momentum of 0.1 is potentially dangerous.
link |
And it might make it so that the running mean and standard
link |
deviation is thrashing too much during training,
link |
and it's not actually converging properly.
link |
Affine equals true determines whether this batch normalization
link |
layer has these learnable affine parameters, the gain
link |
And this is almost always kept to true.
link |
I'm not actually sure why you would
link |
want to change this to false.
link |
Then track running stats is determining whether or not
link |
batch normalization layer of PyTorch will be doing this.
link |
And one reason you may want to skip the running stats
link |
is because you may want to, for example, estimate them
link |
at the end as a stage 2, like this.
link |
And in that case, you don't want the batch normalization
link |
layer to be doing all this extra compute
link |
that you're not going to use.
link |
And finally, we need to know which device
link |
we're going to run this batch normalization on, a CPU
link |
or a GPU, and what the data type should
link |
be, half precision, single precision, double precision,
link |
So that's the batch normalization layer.
link |
Otherwise, they link to the paper.
link |
It's the same formula we've implemented.
link |
And everything is the same, exactly as we've done here.
link |
So that's everything that I wanted to cover for this lecture.
link |
Really, what I wanted to talk about
link |
is the importance of understanding
link |
the activations and the gradients
link |
and their statistics in neural networks.
link |
And this becomes increasingly important,
link |
especially as you make your neural networks bigger, larger,
link |
We looked at the distributions basically at the output layer.
link |
And we saw that if you have too confident mispredictions
link |
because the activations are too messed up at the last layer,
link |
you can end up with these hockey stick losses.
link |
And if you fix this, you get a better loss
link |
at the end of training because your training is not
link |
doing wasteful work.
link |
Then we also saw that we need to control the activations.
link |
We don't want them to squash to zero or explode to infinity.
link |
And because that, you can run into a lot of trouble
link |
with all of these nonlinearities in these neural nets.
link |
And basically, you want everything
link |
to be fairly homogeneous throughout the neural net.
link |
You want roughly Gaussian activations
link |
throughout the neural net.
link |
Then we talked about, OK, if we want roughly Gaussian
link |
activations, how do we scale these weight matrices
link |
and biases during initialization of the neural net
link |
so that we don't get so everything
link |
is as controlled as possible?
link |
So that gave us a large boost in improvement.
link |
And then I talked about how that strategy is not actually
link |
possible for much, much deeper neural nets
link |
because when you have much deeper neural nets with lots
link |
of different types of layers, it becomes really, really hard
link |
to precisely set the weights and the biases in such a way
link |
that the activations are roughly uniform
link |
throughout the neural net.
link |
So then I introduced the notion of a normalization layer.
link |
Now, there are many normalization layers
link |
that people use in practice, batch normalization, layer
link |
normalization, instance normalization,
link |
group normalization.
link |
We haven't covered most of them, but I've
link |
introduced the first one and also the one
link |
that I believe came out first.
link |
And that's called batch normalization.
link |
And we saw how batch normalization works.
link |
This is a layer that you can sprinkle throughout your deep
link |
And the basic idea is if you want roughly Gaussian
link |
activations, well, then take your activations
link |
and take the mean and the standard deviation
link |
and center your data.
link |
And you can do that because the centering operation
link |
is differentiable.
link |
And on top of that, we actually had
link |
to add a lot of bells and whistles.
link |
And that gave you a sense of the complexities
link |
of the batch normalization layer because now we're
link |
centering the data.
link |
But suddenly, we need the gain and the bias.
link |
And now those are trainable.
link |
And then because we are coupling all the training examples,
link |
now suddenly the question is, how do you do the inference?
link |
Well, to do the inference, we need
link |
to now estimate these mean and standard deviation
link |
once over the entire training set
link |
and then use those at inference.
link |
But then no one likes to do stage two.
link |
So instead, we fold everything into the batch normalization
link |
layer during training and try to estimate these
link |
in the running manner so that everything is a bit simpler.
link |
And that gives us the batch normalization layer.
link |
And as I mentioned, no one likes this layer.
link |
It causes a huge amount of bugs.
link |
And intuitively, it's because it is coupling examples
link |
in the forward pass of the neural net.
link |
And I've shot myself in the foot with this layer
link |
over and over again in my life.
link |
And I don't want you to suffer the same.
link |
So basically, try to avoid it as much as possible.
link |
Some of the other alternatives to these layers
link |
are, for example, group normalization
link |
or layer normalization.
link |
And those have become more common in more recent deep
link |
But we haven't covered those yet.
link |
But definitely, batch normalization was very
link |
influential at the time when it came out in roughly 2015.
link |
Because it was kind of the first time
link |
that you could train reliably much deeper neural nets.
link |
And fundamentally, the reason for that
link |
is because this layer was very effective at controlling
link |
the statistics of the activations in the neural net.
link |
So that's the story so far.
link |
And that's all I wanted to cover.
link |
And in the future lectures, hopefully, we
link |
can start going into recurrent neural nets.
link |
And recurrent neural nets, as we'll see,
link |
are just very, very deep networks.
link |
Because you unroll the loop when you actually
link |
optimize these neural nets.
link |
And that's where a lot of this analysis
link |
around the activation statistics and all these normalization
link |
layers will become very, very important for good performance.
link |
So we'll see that next time.
link |
I would like us to do one more summary here as a bonus.
link |
And I think it's useful as to have
link |
one more summary of everything I've
link |
presented in this lecture.
link |
But also, I would like us to start PyTorchifying our code
link |
So it looks much more like what you would encounter in PyTorch.
link |
So you'll see that I will structure our code
link |
into these modules, like a linear module and a batch
link |
And I'm putting the code inside these modules
link |
so that we can construct neural networks very
link |
much like we would construct them in PyTorch.
link |
And I will go through this in detail.
link |
So we'll create our neural net.
link |
Then we will do the optimization loop, as we did before.
link |
And then one more thing that I want to do here
link |
is I want to look at the activation statistics
link |
both in the forward pass and in the backward pass.
link |
And then here we have the evaluation and sampling
link |
So let me rewind all the way up here and go a little bit
link |
So here I am creating a linear layer.
link |
You'll notice that torch.nn has lots
link |
of different types of layers.
link |
And one of those layers is the linear layer.
link |
torch.nn.linear takes a number of input features,
link |
output features, whether or not we should have bias,
link |
and then the device that we want to place this layer on,
link |
and the data type.
link |
So I will omit these two.
link |
But otherwise, we have the exact same thing.
link |
We have the fan in, which is the number of inputs,
link |
fan out, the number of outputs, and whether or not
link |
we want to use a bias.
link |
And internally, inside this layer,
link |
there's a weight and a bias, if you'd like it.
link |
It is typical to initialize the weight using, say,
link |
random numbers drawn from a Gaussian.
link |
And then here's the timing initialization
link |
that we discussed already in this lecture.
link |
And that's a good default, and also the default
link |
that I believe PyTorch uses.
link |
And by default, the bias is usually initialized to zeros.
link |
Now, when you call this module, this
link |
will basically calculate w times x plus b, if you have nb.
link |
And then when you also call the parameters on this module,
link |
it will return the tensors that are
link |
the parameters of this layer.
link |
Now, next, we have the batch normalization layer.
link |
So I've written that here.
link |
And this is very similar to PyTorch's nn.batchnormal1d
link |
layer, as shown here.
link |
So I'm kind of taking these three parameters here,
link |
the dimensionality, the epsilon that we'll use in the division,
link |
and the momentum that we will use
link |
in keeping track of these running stats, the running mean
link |
and the running variance.
link |
Now, PyTorch actually takes quite a few more things,
link |
but I'm assuming some of their settings.
link |
So for us, I find it will be true.
link |
That means that we will be using a gamma and beta
link |
after the normalization.
link |
The track running stats will be true.
link |
So we will be keeping track of the running mean
link |
and the running variance in the batch norm.
link |
Our device, by default, is the CPU.
link |
And the data type, by default, is float, float32.
link |
So those are the defaults.
link |
Otherwise, we are taking all the same parameters
link |
in this batch norm layer.
link |
So first, I'm just saving them.
link |
Now, here's something new.
link |
There's a dot training, which by default is true.
link |
And PyTorch NN modules also have this attribute, dot training.
link |
And that's because many modules, and batch norm
link |
is included in that, have a different behavior
link |
whether you are training your neural net
link |
or whether you are running it in an evaluation mode
link |
and calculating your evaluation loss
link |
or using it for inference on some test examples.
link |
And batch norm is an example of this,
link |
because when we are training, we are
link |
going to be using the mean and the variance estimated
link |
from the current batch.
link |
But during inference, we are using the running mean
link |
and running variance.
link |
And so also, if we are training, we
link |
are updating mean and variance.
link |
But if we are testing, then these are not being updated.
link |
They are kept fixed.
link |
And so this flag is necessary and by default true,
link |
just like in PyTorch.
link |
Now, the parameters of batch norm 1D
link |
are the gamma and the beta here.
link |
And then the running mean and running variance
link |
are called buffers in PyTorch nomenclature.
link |
And these buffers are trained using exponential moving
link |
And they are not part of the back propagation
link |
and stochastic gradient descent.
link |
So they are not sort of like parameters of this layer.
link |
And that's why when we have parameters here,
link |
we only return gamma and beta.
link |
We do not return the mean and the variance.
link |
This is trained sort of like internally
link |
here every forward pass using exponential moving average.
link |
So that's the initialization.
link |
Now, in a forward pass, if we are training,
link |
then we use the mean and the variance estimated by the batch.
link |
Let me pull up the paper here.
link |
We calculate the mean and the variance.
link |
Now, up above, I was estimating the standard deviation
link |
and keeping track of the standard deviation
link |
here in the running standard deviation
link |
instead of running variance.
link |
But let's follow the paper exactly.
link |
Here they calculate the variance, which
link |
is the standard deviation squared.
link |
And that's what's kept track of in the running variance
link |
instead of a running standard deviation.
link |
But those two would be very, very similar, I believe.
link |
If we are not training, then we use running mean and variance.
link |
And then here, I am calculating the output of this layer.
link |
And I'm also assigning it to an attribute called dot out.
link |
Now, dot out is something that I'm using in our modules here.
link |
This is not what you would find in PyTorch.
link |
We are slightly deviating from it.
link |
I'm creating a dot out because I would
link |
have to very easily maintain all those variables so
link |
that we can create statistics of them and plot them.
link |
But PyTorch and modules will not have a dot out attribute.
link |
And finally, here we are updating the buffers using,
link |
again, as I mentioned, exponential moving average
link |
given the provided momentum.
link |
And importantly, you'll notice that I'm
link |
using the torch.nograd context manager.
link |
And I'm doing this because if we don't use this,
link |
then PyTorch will start building out
link |
an entire computational graph out of these tensors
link |
because it is expecting that we will eventually call dot
link |
But we are never going to be calling dot backward
link |
on anything that includes running mean and running
link |
So that's why we need to use this context manager,
link |
so that we are not maintaining and using
link |
all this additional memory.
link |
So this will make it more efficient.
link |
And it's just telling PyTorch that it will be no backward.
link |
We just have a bunch of tensors.
link |
We want to update them.
link |
And then we return.
link |
OK, now scrolling down, we have the 10H layer.
link |
This is very, very similar to torch.10H.
link |
And it doesn't do too much.
link |
It just calculates 10H, as you might expect.
link |
So that's torch.10H.
link |
And there's no parameters in this layer.
link |
But because these are layers, it now
link |
becomes very easy to stack them up into basically just a list.
link |
And we can do all the initializations
link |
that we're used to.
link |
So we have the initial embedding matrix.
link |
We have our layers, and we can call them sequentially.
link |
And then, again, with torch.nograd,
link |
there's some initializations here.
link |
So we want to make the output softmax a bit less confident,
link |
And in addition to that, because we are using a six-layer
link |
multilayer perceptron here, so you
link |
see how I'm stacking linear 10H, linear 10H, et cetera,
link |
I'm going to be using the game here.
link |
And I'm going to play with this in a second.
link |
So you'll see how, when we change this,
link |
what happens to the statistics.
link |
Finally, the parameters are basically the embedding matrix
link |
and all the parameters in all the layers.
link |
And notice here, I'm using a double list comprehension,
link |
if you want to call it that.
link |
But for every layer in layers and for every parameter
link |
in each of those layers, we are just stacking up
link |
all those pieces, all those parameters.
link |
Now, in total, we have 46,000 parameters.
link |
And I'm telling PyTorch that all of them require gradient.
link |
Then here, we have everything here
link |
we are actually mostly used to.
link |
We are sampling batch.
link |
We are doing a forward pass.
link |
The forward pass now is just the linear application
link |
of all the layers in order, followed by the cross entropy.
link |
And then in the backward pass, you'll
link |
notice that for every single layer,
link |
I now iterate over all the outputs.
link |
And I'm telling PyTorch to retain the gradient of them.
link |
And then here, we are already used to all the gradients
link |
set to none, do the backward to fill in the gradients,
link |
do an update using stochastic gradient send,
link |
and then track some statistics.
link |
And then I am going to break after a single iteration.
link |
Now, here in this cell, in this diagram,
link |
I'm visualizing the histograms of the forward pass activations.
link |
And I'm specifically doing it at the 10H layers.
link |
So iterating over all the layers,
link |
except for the very last one, which is basically just the soft
link |
max layer, if it is a 10H layer, and I'm using a 10H layer
link |
just because they have a finite output, negative 1 to 1,
link |
and so it's very easy to visualize here.
link |
So you see negative 1 to 1, and it's a finite range,
link |
and easy to work with.
link |
I take the out tensor from that layer into t.
link |
And then I'm calculating the mean, the standard deviation,
link |
and the percent saturation of t.
link |
And the way I define the percent saturation
link |
is that t dot absolute value is greater than 0.97.
link |
So that means we are here at the tails of the 10H.
link |
And remember that when we are in the tails of the 10H,
link |
that will actually stop gradients.
link |
So we don't want this to be too high.
link |
Now, here I'm calling torch dot histogram,
link |
and then I am plotting this histogram.
link |
So basically what this is doing is
link |
that every different type of layer,
link |
and they all have a different color,
link |
we are looking at how many values in these tensors
link |
take on any of the values below on this axis here.
link |
So the first layer is fairly saturated here at 20%.
link |
So you can see that it's got tails here.
link |
But then everything sort of stabilizes.
link |
And if we had more layers here, it
link |
would actually just stabilize at around the standard deviation
link |
of about 0.65, and the saturation would be roughly 5%.
link |
And the reason that this stabilizes and gives us
link |
a nice distribution here is because gain
link |
is set to 5 over 3.
link |
Now, here, this gain, you see that by default, we
link |
initialize with 1 over square root of fan in.
link |
But then here, during initialization,
link |
I come in and I iterate over all the layers.
link |
And if it's a linear layer, I boost that by the gain.
link |
Now, we saw that 1.
link |
So basically, if we just do not use a gain, then what happens?
link |
If I redraw this, you will see that the standard deviation
link |
is shrinking, and the saturation is coming to 0.
link |
And basically, what's happening is
link |
the first layer is pretty decent,
link |
but then further layers are just kind of like shrinking down
link |
And it's happening slowly, but it's shrinking to 0.
link |
And the reason for that is when you just
link |
have a sandwich of linear layers alone,
link |
then initializing our weights in this manner we saw previously
link |
would have conserved the standard deviation of 1.
link |
But because we have this interspersed tanh layers
link |
in there, these tanh layers are squashing functions.
link |
And so they take your distribution,
link |
and they slightly squash it.
link |
And so some gain is necessary to keep expanding it
link |
to fight the squashing.
link |
So it just turns out that 5 over 3 is a good value.
link |
So if we have something too small, like 1,
link |
we saw that things will come towards 0.
link |
But if it's something too high, let's do 2.
link |
Then here we see that, well, let me
link |
do something a bit more extreme so it's a bit more visible.
link |
OK, so we see here that the saturations are
link |
trying to be way too large.
link |
So 3 would create way too saturated activations.
link |
So 5 over 3 is a good setting for a sandwich of linear layers
link |
with tanh activations.
link |
And it roughly stabilizes the standard deviation
link |
at a reasonable point.
link |
Now, honestly, I have no idea where 5 over 3
link |
came from in PyTorch when we were looking
link |
at the counting initialization.
link |
I see empirically that it stabilizes
link |
this sandwich of linear and tanh,
link |
and that the saturation is in a good range.
link |
But I don't actually know if this came out of some math
link |
I tried searching briefly for where this comes from,
link |
but I wasn't able to find anything.
link |
But certainly, we see that empirically,
link |
these are very nice ranges.
link |
Our saturation is roughly 5%, which is a pretty good number.
link |
And this is a good setting of the gain in this context.
link |
Similarly, we can do the exact same thing with the gradients.
link |
So here is a very same loop if it's a tanh.
link |
But instead of taking the layer that out, I'm taking the grad.
link |
And then I'm also showing the mean and the standard deviation.
link |
And I'm plotting the histogram of these values.
link |
And so you'll see that the gradient distribution
link |
is fairly reasonable.
link |
And in particular, what we're looking for
link |
is that all the different layers in this sandwich
link |
has roughly the same gradient.
link |
Things are not shrinking or exploding.
link |
So we can, for example, come here,
link |
and we can take a look at what happens if this gain was way
link |
Then you see, first of all, the activations
link |
are shrinking to 0.
link |
But also, the gradients are doing something weird.
link |
The gradients started out here, and then now they're
link |
like expanding out.
link |
And similarly, if we, for example,
link |
have a too high of a gain, so like 3,
link |
then we see that also the gradients have some asymmetry
link |
going on, where as you go into deeper and deeper layers,
link |
the activations are also changing.
link |
And so that's not what we want.
link |
And in this case, we saw that without the use of batch norm,
link |
as we are going through right now,
link |
we have to very carefully set those gains
link |
to get nice activations in both the forward pass
link |
and the backward pass.
link |
Now, before we move on to batch normalization,
link |
I would also like to take a look at what happens when we have no
link |
So erasing all the 10H nonlinearities,
link |
but keeping the gain at 5 over 3,
link |
we now have just a giant linear sandwich.
link |
So let's see what happens to the activations.
link |
As we saw before, the correct gain here
link |
is 1, that is the standard deviation preserving gain.
link |
So 1.667 is too high.
link |
And so what's going to happen now is the following.
link |
I have to change this to be linear,
link |
because there's no more 10H layers.
link |
And let me change this to linear as well.
link |
So what we're seeing is the activations started out
link |
on the blue and have, by layer 4, become very diffuse.
link |
So what's happening to the activations is this.
link |
And with the gradients on the top layer,
link |
the gradient statistics are the purple,
link |
and then they diminish as you go down deeper in the layers.
link |
And so basically, you have an asymmetry in the neural net.
link |
And you might imagine that if you
link |
have very deep neural networks, say like 50 layers
link |
or something like that, this is not a good place to be.
link |
So that's why, before batch normalization,
link |
this was incredibly tricky to set.
link |
In particular, if this is too large of a gain, this happens.
link |
And if it's too little of a gain, then this happens.
link |
So the opposite of that basically happens.
link |
Here we have a shrinking and a diffusion,
link |
depending on which direction you look at it from.
link |
And so certainly, this is not what you want.
link |
And in this case, the correct setting of the gain
link |
is exactly 1, just like we're doing at initialization.
link |
And then we see that the statistics
link |
for the forward and the backward paths are well-behaved.
link |
And so the reason I want to show you this
link |
is that basically, getting neural nets to train
link |
before these normalization layers
link |
and before the use of advanced optimizers like Adam,
link |
which we still have to cover, and residual connections
link |
and so on, training neural nets basically look like this.
link |
It's like a total balancing act.
link |
You have to make sure that everything is precisely
link |
And you have to care about the activations and the gradients
link |
and their statistics.
link |
And then maybe you can train something.
link |
But it was basically impossible to train very deep networks.
link |
And this is fundamentally the reason for that.
link |
You'd have to be very, very careful
link |
with your initialization.
link |
The other point here is you might be asking yourself,
link |
by the way, I'm not sure if I covered this,
link |
why do we need these 10H layers at all?
link |
Why do we include them and then have to worry about the gain?
link |
And the reason for that, of course,
link |
is that if you just have a stack of linear layers,
link |
then certainly, we're getting very easily nice activations
link |
But this is just a massive linear sandwich.
link |
And it turns out that it collapses
link |
to a single linear layer in terms
link |
of its representation power.
link |
So if you were to plot the output
link |
as a function of the input, you're
link |
just getting a linear function.
link |
No matter how many linear layers you stack up,
link |
you still just end up with a linear transformation.
link |
All the wx plus bs just collapse into a large wx plus b
link |
with slightly different ws and slightly different b.
link |
But interestingly, even though the forward pass collapses
link |
to just a linear layer, because of back propagation
link |
and the dynamics of the backward pass,
link |
the optimization actually is not identical.
link |
You actually end up with all kinds
link |
of interesting dynamics in the backward pass
link |
because of the way the chain rule is calculating it.
link |
And so optimizing a linear layer by itself
link |
and optimizing a sandwich of 10 linear layers, in both cases,
link |
those are just a linear transformation
link |
in the forward pass, but the training dynamics
link |
will be different.
link |
And there's entire papers that analyze, in fact,
link |
infinitely linear layers and so on.
link |
And so there's a lot of things, too,
link |
that you can play with there.
link |
But basically, the 10H nonlinearities
link |
allow us to turn this sandwich from just a linear function
link |
into a neural network that can, in principle,
link |
approximate any arbitrary function.
link |
OK, so now I've reset the code to use the linear 10H
link |
sandwich, like before.
link |
And I reset everything so the gain is 5 over 3.
link |
We can run a single step of optimization,
link |
and we can look at the activation statistics
link |
of the forward pass and the backward pass.
link |
But I've added one more plot here
link |
that I think is really important to look
link |
at when you're training your neural nets and to consider.
link |
And ultimately, what we're doing is
link |
we're updating the parameters of the neural net.
link |
So we care about the parameters and their values
link |
and their gradients.
link |
So here, what I'm doing is I'm actually
link |
iterating over all the parameters available,
link |
and then I'm only restricting it to the two-dimensional
link |
parameters, which are basically the weights of these linear
link |
And I'm skipping the biases, and I'm
link |
skipping the gammas and the betas and the bastroom
link |
just for simplicity.
link |
But you can also take a look at those as well.
link |
But what's happening with the weights
link |
is instructive by itself.
link |
So here we have all the different weights,
link |
So this is the embedding layer, the first linear layer,
link |
all the way to the very last linear layer.
link |
And then we have the mean, the standard deviation
link |
of all these parameters.
link |
The histogram, and you can see that it actually
link |
doesn't look that amazing.
link |
So there's some trouble in paradise.
link |
Even though these gradients look OK,
link |
there's something weird going on here.
link |
I'll get to that in a second.
link |
And the last thing here is the gradient-to-data ratio.
link |
So sometimes I like to visualize this as well
link |
because what this gives you a sense of
link |
is what is the scale of the gradient compared
link |
to the scale of the actual values?
link |
And this is important because we're
link |
going to end up taking a step update that
link |
is the learning rate times the gradient onto the data.
link |
And so if the gradient has too large of a magnitude,
link |
if the numbers in there are too large
link |
compared to the numbers in data, then you'd be in trouble.
link |
But in this case, the gradient-to-data
link |
is our low numbers.
link |
So the values inside grad are 1,000 times
link |
smaller than the values inside data in these weights, most
link |
Now, notably, that is not true about the last layer.
link |
And so the last layer actually here, the output layer,
link |
is a bit of a troublemaker in the way
link |
that this is currently arranged.
link |
Because you can see that the last layer here in pink
link |
takes on values that are much larger than some
link |
of the values inside the neural net.
link |
So the standard deviations are roughly 1 and negative 3
link |
throughout, except for the last layer, which actually has
link |
roughly 1 and negative 2 standard deviation
link |
And so the gradients on the last layer
link |
are currently about 10 times greater
link |
than all the other weights inside the neural net.
link |
And so that's problematic, because in the simple
link |
stochastic gradedness setup, you would
link |
be training this last layer about 10 times faster
link |
than you would be training the other layers
link |
at initialization.
link |
Now, this actually kind of fixes itself a little bit
link |
if you train for a bit longer.
link |
So for example, if I greater than 1,000,
link |
only then do a break.
link |
Let me reinitialize.
link |
And then let me do it 1,000 steps.
link |
And after 1,000 steps, we can look at the forward pass.
link |
So you see how the neurons are saturating a bit.
link |
And we can also look at the backward pass.
link |
But otherwise, they look good.
link |
They're about equal.
link |
And there's no shrinking to 0 or exploding to infinities.
link |
And you can see that here in the weights,
link |
things are also stabilizing a little bit.
link |
So the tails of the last pink layer
link |
are actually coming in during the optimization.
link |
But certainly, this is a little bit troubling,
link |
especially if you are using a very simple update rule,
link |
like stochastic gradient descent,
link |
instead of a modern optimizer like Atom.
link |
Now, I'd like to show you one more plot that I usually
link |
look at when I train neural networks.
link |
And basically, the gradient to data ratio
link |
is not actually that informative,
link |
because what matters at the end is not the gradient to data
link |
ratio, but the update to the data ratio,
link |
because that is the amount by which we will actually
link |
change the data in these tensors.
link |
So coming up here, what I'd like to do
link |
is I'd like to introduce a new update to data ratio.
link |
It's going to be list, and we're going to build it out
link |
every single iteration.
link |
And here, I'd like to keep track of basically the ratio
link |
every single iteration.
link |
So without any gradients, I'm comparing the update,
link |
which is learning rate times the gradient.
link |
That is the update that we're going to apply
link |
to every parameter.
link |
So see, I'm iterating over all the parameters.
link |
And then I'm taking the standard deviation of the update
link |
we're going to apply and divide it
link |
by the actual content, the data of that parameter,
link |
and its standard deviation.
link |
So this is the ratio of basically how great
link |
are the updates to the values in these tensors.
link |
Then we're going to take a log of it,
link |
and actually, I'd like to take a log 10,
link |
just so it's a nicer visualization.
link |
So we're going to be basically looking
link |
at the exponents of this division here,
link |
and then dot item to pop out the float.
link |
And we're going to be keeping track of this
link |
for all the parameters and adding it to this UD tensor.
link |
So now let me re-initialize and run 1,000 iterations.
link |
We can look at the activations, the gradients,
link |
and the parameter gradients as we did before.
link |
But now I have one more plot here to introduce.
link |
What's happening here is where every interval load parameters,
link |
and I'm constraining it again, like I did here,
link |
to just the weights.
link |
So the number of dimensions in these sensors is 2.
link |
And then I'm basically plotting all of these update ratios
link |
So when I plot this, I plot those ratios,
link |
and you can see that they evolve over time during initialization
link |
to take on certain values.
link |
And then these updates start stabilizing
link |
usually during training.
link |
Then the other thing that I'm plotting here
link |
is I'm plotting here an approximate value that
link |
is a rough guide for what it roughly should be.
link |
And it should be roughly 1 in negative 3.
link |
And so that means that basically there's
link |
some values in this tensor, and they take on certain values.
link |
And the updates to them at every single iteration
link |
are no more than roughly 1,000 of the actual magnitude
link |
If this was much larger, like for example,
link |
if the log of this was, like, say, negative 1,
link |
this is actually updating those values quite a lot.
link |
They're undergoing a lot of change.
link |
But the reason that the final layer here is an outlier
link |
is because this layer was artificially shrunk down
link |
to keep the softmax unconfident.
link |
So here, you see how we multiplied the weight by 0.1
link |
in the initialization to make the last layer
link |
prediction less confident.
link |
That artificially made the values inside that tensor way
link |
too low, and that's why we're getting temporarily
link |
a very high ratio.
link |
But you see that that stabilizes over time
link |
once that weight starts to learn.
link |
But basically, I like to look at the evolution of this update
link |
ratio for all my parameters, usually.
link |
And I like to make sure that it's not too much
link |
above 1 in negative 3, roughly.
link |
So around negative 3 on this log plot.
link |
If it's below negative 3, usually that
link |
means that the parameters are not training fast enough.
link |
So if our learning rate was very low, let's do that experiment.
link |
And then let's actually do a learning rate
link |
of, say, 1 in negative 3 here, so 0.001.
link |
If your learning rate is way too low,
link |
this plot will typically reveal it.
link |
So you see how all of these updates are way too small.
link |
So the size of the update is basically 10,000 times
link |
in magnitude to the size of the numbers
link |
in that tensor in the first place.
link |
So this is a symptom of training way too slow.
link |
So this is another way to sometimes set the learning
link |
rate and to get a sense of what that learning rate should be.
link |
And ultimately, this is something
link |
that you would keep track of.
link |
If anything, the learning rate here
link |
is a little bit on the higher side
link |
because you see that we're above the black line of negative 3.
link |
We're somewhere around negative 2.5.
link |
But everything is somewhat stabilizing.
link |
And so this looks like a pretty decent setting
link |
of learning rates and so on.
link |
But this is something to look at.
link |
And when things are miscalibrated,
link |
you will see very quickly.
link |
So for example, everything looks pretty well-behaved.
link |
But just as a comparison, when things are not properly
link |
calibrated, what does that look like?
link |
Let me come up here.
link |
And let's say that, for example, what do we do?
link |
Let's say that we forgot to apply this fan-in normalization.
link |
So the weights inside the linear layers
link |
are just a sample from a Gaussian in all the stages.
link |
What happens to our, how do we notice that something's off?
link |
Well, the activation plot will tell you, whoa,
link |
your neurons are way too saturated.
link |
The gradients are going to be all messed up.
link |
The histogram for these weights are going to be all messed up
link |
And there's a lot of asymmetry.
link |
And then if we look here, I suspect
link |
it's all going to be also pretty messed up.
link |
So you see there's a lot of discrepancy
link |
in how fast these layers are learning.
link |
And some of them are learning way too fast.
link |
So negative 1, negative 1.5, those
link |
are very large numbers in terms of this ratio.
link |
Again, you should be somewhere around the range of 1.5
link |
or, again, you should be somewhere around negative 3
link |
and not much more above that.
link |
So this is how miscalibrations of your neural nets
link |
are going to manifest.
link |
And these kinds of plots here are
link |
a good way of sort of bringing those miscalibrations sort
link |
of to your attention and so you can address them.
link |
OK, so far we've seen that when we have this linear 10H
link |
sandwich, we can actually precisely calibrate the gains
link |
and make the activations, the gradients, and the parameters,
link |
and the updates all look pretty decent.
link |
But it definitely feels a little bit like balancing
link |
of a pencil on your finger.
link |
And that's because this gain has to be very precisely
link |
So now let's introduce batch normalization layers
link |
And let's see how that helps fix the problem.
link |
So here, I'm going to take the batch from 1D class.
link |
And I'm going to start placing it inside.
link |
And as I mentioned before, the standard typical place
link |
you would place it is between the linear layer,
link |
so right after it, but before the nonlinearity.
link |
But people have definitely played with that.
link |
And in fact, you can get very similar results
link |
even if you place it after the nonlinearity.
link |
And the other thing that I wanted to mention
link |
is it's totally fine to also place it
link |
at the end after the last linear layer
link |
and before the loss function.
link |
So this is potentially fine as well.
link |
And in this case, this would be output, would be vocab size.
link |
Now, because the last layer is batch room,
link |
we would not be changing the weight
link |
to make the softmax less confident.
link |
We'd be changing the gamma.
link |
Because gamma, remember, in the batch room
link |
is the variable that multiplicatively
link |
interacts with the output of that normalization.
link |
So we can initialize this sandwich now.
link |
And we can see that the activations are going
link |
to, of course, look very good.
link |
And they are going to necessarily look good.
link |
Because now before every single 10H layer,
link |
there is a normalization in the batch room.
link |
So this is, unsurprisingly, all looks pretty good.
link |
It's going to be standard deviation of roughly 0.65%,
link |
2%, and roughly equal standard deviation
link |
throughout the entire layers.
link |
So everything looks very homogeneous.
link |
The gradients look good.
link |
The weights look good.
link |
And their distributions.
link |
And then the updates also look pretty reasonable.
link |
We are going above negative 3 a little bit, but not by too much.
link |
So all the parameters are training at roughly the same
link |
But now what we've gained is we are
link |
going to be slightly less brittle with respect
link |
to the gain of these.
link |
So for example, I can make the gain be, say, 0.2 here,
link |
which is much slower than what we had with the 10H.
link |
But as we'll see, the activations
link |
will actually be exactly unaffected.
link |
And that's because of, again, this explicit normalization.
link |
The gradients are going to look OK.
link |
The weight gradients are going to look OK.
link |
But actually, the updates will change.
link |
And so even though the forward and backward paths,
link |
to a very large extent, look OK because of the backward paths
link |
of the batch norm and how the scale of the incoming
link |
activations interacts in the batch norm
link |
and its backward paths, this is actually
link |
changing the scale of the updates on these parameters.
link |
So the gradients of these weights are affected.
link |
So we still don't get a completely free pass
link |
to pass in arbitrary weights here.
link |
But everything else is significantly more robust
link |
in terms of the forward, backward, and the weight gradients.
link |
It's just that you may have to retune your learning rate
link |
if you are changing sufficiently the scale of the activations
link |
that are coming into the batch norms.
link |
So here, for example, we changed the gains
link |
of these linear layers to be greater.
link |
And we're seeing that the updates are coming out lower
link |
And then finally, we can also, if we are using batch norms,
link |
we don't actually need to necessarily,
link |
let me reset this to 1 so there's no gain.
link |
We don't necessarily even have to normalize by fan-in sometimes.
link |
So if I take out the fan-in, so these are just now
link |
random Gaussian, we'll see that because of batch norm,
link |
this will actually be relatively well-behaved.
link |
So this look, of course, in the forward pass look good.
link |
The gradients look good.
link |
The backward weight updates look OK.
link |
A little bit of fat tails on some of the layers.
link |
And this looks OK as well.
link |
But as you can see, we're significantly below negative 3.
link |
So we'd have to bump up the learning rate
link |
of this batch norm so that we are training more properly.
link |
And in particular, looking at this,
link |
roughly looks like we have to 10x the learning rate
link |
to get to about 1e negative 3.
link |
So we'd come here, and we would change this to be update of 1.0.
link |
And if I reinitialize, then we'll
link |
see that everything still, of course, looks good.
link |
And now we are roughly here.
link |
And we expect this to be an OK training run.
link |
So long story short, we are significantly more robust
link |
to the gain of these linear layers,
link |
whether or not we have to apply the fan-in.
link |
And then we can change the gain, but we actually
link |
do have to worry a little bit about the update scales
link |
and making sure that the learning rate is properly
link |
But the activations of the forward, backward pass
link |
and the updates are looking significantly more well
link |
behaved, except for the global scale that is potentially
link |
being adjusted here.
link |
OK, so now let me summarize.
link |
There are three things I was hoping
link |
to achieve with this section.
link |
Number one, I wanted to introduce you
link |
to batch normalization, which is one
link |
of the first modern innovations that we're
link |
looking into that helped stabilize
link |
very deep neural networks and their training.
link |
And I hope you understand how the batch normalization works
link |
and how it would be used in a neural network.
link |
Number two, I was hoping to PyTorchify some of our code
link |
and wrap it up into these modules,
link |
so like linear, batch norm 1D, 10H, et cetera.
link |
These are layers or modules.
link |
And they can be stacked up into neural nets
link |
like Lego building blocks.
link |
And these layers actually exist in PyTorch.
link |
And if you import torch nn, then you can actually,
link |
the way I've constructed it, you can
link |
simply just use PyTorch by prepending nn.
link |
to all these different layers.
link |
And actually, everything will just
link |
work because the API that I've developed here
link |
is identical to the API that PyTorch uses.
link |
And the implementation also is basically,
link |
as far as I'm aware, identical to the one in PyTorch.
link |
And number three, I tried to introduce you
link |
to the diagnostic tools that you would
link |
use to understand whether your neural network is
link |
in a good state dynamically.
link |
So we are looking at the statistics and histograms
link |
and activation of the forward pass activations,
link |
the backward pass gradients.
link |
And then also, we're looking at the weights
link |
that are going to be updated as part of stochastic gradient
link |
And we're looking at their means, standard deviations,
link |
and also the ratio of gradients to data,
link |
or even better, the updates to data.
link |
And we saw that typically, we don't actually
link |
look at it as a single snapshot frozen in time
link |
at some particular iteration.
link |
Typically, people look at this as over time,
link |
just like I've done here.
link |
And they look at these update-to-data ratios,
link |
and they make sure everything looks OK.
link |
And in particular, I said that running negative 3,
link |
or basically negative 3 on the log scale,
link |
is a good rough heuristic for what
link |
you want this ratio to be.
link |
And if it's way too high, then probably the learning rate
link |
or the updates are a little too big.
link |
And if it's way too small, then the learning rate
link |
is probably too small.
link |
So that's just some of the things
link |
that you may want to play with when
link |
you try to get your neural network to work very well.
link |
Now, there's a number of things I did not try to achieve.
link |
I did not try to beat our previous performance,
link |
as an example, by introducing the BashNorm layer.
link |
Actually, I did try.
link |
And I used the learning rate finding mechanism
link |
that I've described before.
link |
I tried to train the BashNorm layer, BashNorm neural net.
link |
And I actually ended up with results
link |
that are very, very similar to what we've obtained before.
link |
And that's because our performance now
link |
is not bottlenecked by the optimization, which
link |
is what BashNorm is helping with.
link |
The performance at this stage is bottlenecked by, what I
link |
suspect, is the context length of our context.
link |
So currently, we are taking three characters
link |
to predict the fourth one.
link |
And I think we need to go beyond that.
link |
And we need to look at more powerful architectures,
link |
like recurrent neural networks and transformers,
link |
in order to further push the log probabilities that we're
link |
achieving on this data set.
link |
And I also did not try to have a full explanation of all
link |
of these activations, the gradients,
link |
and the backward pass, and the statistics
link |
of all these gradients.
link |
And so you may have found some of the parts here unintuitive.
link |
And maybe you were slightly confused about, OK,
link |
if I change the game here, how come that we need
link |
a different learning rate?
link |
And I didn't go into the full detail
link |
because you'd have to actually look
link |
at the backward pass of all these different layers
link |
and get an intuitive understanding
link |
of how that works.
link |
And I did not go into that in this lecture.
link |
The purpose really was just to introduce you
link |
to the diagnostic tools and what they look like.
link |
But there's still a lot of work remaining on the intuitive
link |
level to understand the initialization,
link |
the backward pass, and how all of that interacts.
link |
But you shouldn't feel too bad because, honestly, we
link |
are getting to the cutting edge of where the field is.
link |
We certainly haven't, I would say, solved initialization.
link |
And we haven't solved backpropagation.
link |
And these are still very much an active area of research.
link |
People are still trying to figure out
link |
what is the best way to initialize these networks,
link |
what is the best update rule to use, and so on.
link |
So none of this is really solved.
link |
And we don't really have all the answers
link |
to all these cases.
link |
But at least we're making progress.
link |
And at least we have some tools to tell us
link |
whether or not things are on the right track for now.
link |
So I think we've made positive progress in this lecture.
link |
And I hope you enjoyed that.
link |
And I will see you next time.